the study of speech sounds and their physiological production and acoustic qualities. It deals with the configurations of the vocal tract used to produce speech sounds (articulatory phonetics), the acoustic properties of speech sounds (acoustic phonetics), and the manner of combining sounds so as to make syllables, words, and sentences (linguistic phonetics).
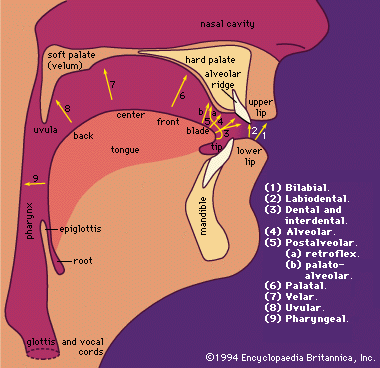
The traditional method of describing speech sounds is in terms of the movements of the vocal organs that produce them. The main structures that are important in the production of speech are the lungs and the respiratory system, together with the vocal organs shown in Figure 1.
The airstream from the lungs passes between the vocal cords, which are two small muscular folds located in the larynx at the top of the windpipe. The space between the vocal cords is known as the glottis. If the vocal cords are apart, as they are normally when breathing out, the air from the lungs will have a relatively free passage into the pharynx (see Figure 1 ) and the mouth. But if the vocal cords are adjusted so that there is a narrow passage between them, the airstream will cause them to be sucked together. As soon as they are together there will be no flow of air, and the pressure below them will be built up until they are blown apart again. The flow of air between them will then cause them to be sucked together again, and the vibratory cycle will continue. Sounds produced when the vocal cords are vibrating are said to be voiced, as opposed to those in which the vocal cords are apart, which are said to be voiceless.
The air passages above the vocal cords are known collectively as the vocal tract. For phonetic purposes they may be divided into the oral tract within the mouth and the pharynx, and the nasal tract within the nose. Many speech sounds are characterized by movements of the lower articulators--i.e., the tongue or the lower lip--toward the upper articulators within the oral tract. The upper surface includes several important structures from the point of view of speech production, such as the upper lip and the upper teeth; Figure 1 illustrates most of the terms that are commonly used. The alveolar ridge is a small protuberance just behind the upper front teeth that can easily be felt with the tongue. The major part of the roof of the mouth is formed by the hard palate in the front, and the soft palate or velum at the back. The soft palate is a muscular flap that can be raised so as to shut off the nasal tract and prevent air from going out through the nose. When it is raised so that the soft palate is pressed against the back wall of the pharynx there is said to be a velic closure. At the lower end of the soft palate is a small hanging appendage known as the uvula.
As may be seen from Figure 1 , there are also specific names for different parts of the tongue. The tip and blade are the most mobile parts. Behind the blade is the so-called front of the tongue; it is actually the forward part of the body of the tongue and lies underneath the hard palate when the tongue is at rest. The remainder of the body of the tongue may be divided into the centre, which is partly beneath the hard palate and partly beneath the soft palate; the back, which is beneath the soft palate; and the root, which is opposite the back wall of the pharynx.
The major division in speech sounds is that between vowels and consonants. Phoneticians have found it difficult to give a precise definition of the articulatory distinction between these two classes of sounds. Most authorities would agree that a vowel is a sound that is produced without any major constrictions in the vocal tract, so that there is a relatively free passage for the air. It is also syllabic. This description is unsatisfactory in that no adequate definition of the notion syllabic has yet been formulated.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
In the formation of consonants, the airstream through the vocal tract is obstructed in some way. Consonants can be classified according to the place and manner of this obstruction. Some of the possible places of articulation are indicated by the arrows going from one of the lower articulators to one of the upper articulators in Figure 1
Location of vocal organs and possible places of articulation.. The principal terms that are required in the description of English articulation, and the structures of the vocal tract that they involve are: bilabial, the two lips; dental, tongue tip or blade and the upper front teeth; alveolar, tongue tip or blade and the teeth ridge; retroflex, tongue tip and the back part of the teeth ridge; palato-alveolar, tongue blade and the back part of the teeth ridge; palatal, front of tongue and hard palate; and velar, back of tongue and soft palate. The additional places of articulation shown in Figure 1 are required in the description of other languages. Note that the terms for the various places of articulation denote both the portion of the lower articulators (i.e., lower lip and tongue) and the portion of the upper articulatory structures that are involved. Thus velar denotes a sound in which the back of the tongue and the soft palate are involved, and retroflex implies a sound involving the tip of the tongue and the back part of the alveolar ridge. If it is necessary to distinguish between sounds made with the tip of the tongue and those made with the blade, the terms apical (tip) and laminal (blade) may be used.
There are six basic manners of articulation that can be used at these places of articulation: stop, fricative, approximant, trill, tap, and lateral.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Stops involve closure of the articulators to obstruct the airstream. This manner of articulation can be considered in terms of nasal and oral stops. If the soft palate is down so that air can still go out through the nose, there is said to be a nasal stop. Sounds of this kind occur at the beginning of the words my and nigh. If, in addition to the articulatory closure in the mouth, the soft palate is raised so that the nasal tract is blocked off, then the airstream will be completely obstructed, the pressure in the mouth will be built up, and an oral stop will be formed. When the articulators open the airstream will be released with a plosive quality. This kind of sound occurs in the consonants in the words pie, tie, kye, buy, die, and guy. Many authorities refer to these two articulations as nasals, meaning nasal stops (closure of the articulators in the oral tract), and stops, meaning oral stops (raising of the soft palate to form a velic closure).
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
A fricative sound involves the close approximation of two articulators, so that the airstream is partially obstructed and a turbulent airflow is produced. The mechanisms used in the production of these sounds may be compared to the physical forces involved when the wind "whistles" round a corner. Examples are the initial sounds in the words fie, thigh, sigh, and shy. Some authorities divide fricatives into slit and grooved fricatives, or rill and flat fricatives, depending on the shape of the constriction in the mouth required to produce them. Other authorities divide fricatives into sibilants, as in sigh and shy, and nonsibilants, as in fie and thigh. This division is based on acoustic criteria (see below).
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Approximants are produced when one articulator approaches another but does not make the vocal tract so narrow that a turbulent airstream results. The terms frictionless continuant, semivowel, and glide are sometimes used for some of the sounds made with this manner of articulation. The consonants in the words we and you are examples of approximants.
A trill results when an articulator is held loosely fairly close to another articulator, so that it is set into vibration by the airstream. The tongue tip and blade, the uvula, and the lips are the only articulators than can be used in this way. Tongue tip trills occur in some forms of Scottish English in words such as rye and ire. Uvular trills are comparatively rare but are used in some dialects of French, but not Parisian French. Trills of the lips are even rarer but do occur in a few African languages.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
A tap is produced if one articulator is thrown against another, as when the loosely held tongue tip makes a single tap against the upper teeth or the alveolar ridge. The consonant in the middle of a word such as letter or Betty is often made in this way in American English. The term flap is also used to describe these sounds, but some authorities make a distinction between taps as defined here and flaps, in which the tip of the tongue is raised up and back and then strikes the alveolar ridge as it returns to a position behind the lower front teeth. Some languages--e.g., Hausa, the principal language of Northern Nigeria--distinguish between words containing a flap and words containing a tap. The distinction between a trill and a tap is used in Spanish to distinguish between words such as perro, meaning "dog," and pero, meaning "but."
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
When the airstream is obstructed in the mid-line of the oral tract, and there is incomplete closure between one or both sides of the tongue and the roof of the mouth, the resulting sound is classified as a lateral. The sounds at the beginning and end of the word lull are laterals in most forms of American English.
The production of many sounds involves more than one of these six basic manners of articulation. The sounds at the beginning and end of the word church are stops combined with fricatives. The articulators--tongue tip or blade, and alveolar ridge--come together for the stop, and then, instead of coming fully apart, they separate only slightly so that a fricative is made at the same place of articulation. This kind of combination is called an affricate. Lateral articulations may also occur in combination with other manners of articulation. The laterals in a word such as lull might more properly be called lateral approximants, in that the airstream passes out freely between the sides of the tongue and the roof of the mouth without a turbulent airstream being produced. But in some sounds in other languages the sides of the tongue are closer to the roof of the mouth and a lateral fricative occurs; an example is the sound spelled ll in Welsh words such as llan "church" and the name Lluellyn.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
When an approximant articulation occurs at the same time as another articulation is being made at a different place in the vocal tract, the approximant is said to form a secondary articulation. There are special terms for some of these possibilities. Added lip rounding is called labialization; it occurs in the formation of several English sounds--e.g., during the pronunciation of the palato-alveolar fricative at the beginning of the word shoe. Raising of the front of the tongue while simultaneously making another articulation elsewhere in the vocal tract is called palatalization. It is the distinguishing characteristic of the soft consonants in Russian and also occurs, to a lesser extent, in English; e.g., in the first consonant in the word leaf. Raising of the back of the tongue to form a secondary articulation is called velarization; it occurs in the last consonant in the word feel, which therefore does not contain the same sounds as those in the reverse order in the word leaf. Retracting of the root of the tongue while making another articulation is called pharyngealization; it occurs in Arabic in what are called emphatic consonants.
The states of the glottis, places of articulation, and manners of articulation discussed above are sufficient to distinguish between the major contrasts among the consonants of English and many other languages. But additional possibilities have to be taken into account in a more detailed description of English, or in descriptions of several other languages. Among these possibilities are variations in the timing of the states of the glottis. In addition to the contrast between the voiced and voiceless states of the glottis that occur during an articulation, there may be variations in the state of the glottis during the release of the articulation. Thus both the p in pin and that in spin are voiceless bilabial stops, but they differ in that the glottis remains in a voiceless position for a short time after the release of the bilabial stop in pin, whereas in spin the voicing starts as soon as the lips come apart. When there is a period of voicelessness during the release of an articulation, the sound is said to be aspirated. The main difference between the consonants in pea and bee, when these words are said in isolation, is not that the one is voiceless and the other voiced, but that the first is aspirated and the second is unaspirated. Some languages distinguish between both voiced-voiceless and aspirated-unaspirated sounds. Thus Thai has contrasts between voiceless aspirated stops, voiceless unaspirated stops, and voiced unaspirated stops.
Several languages use more than just the voiced and voiceless states of the glottis. In Hindi and many of the other languages of India, some sounds are produced while the vocal cords are vibrating for part of their length but are apart, so that a considerable amount of air escapes between them at one end. This phenomenon is known as breathy voice, or murmur. Other languages have sounds in which the vocal cords are held tightly together so that only part of their length can vibrate. This kind of sound, which is usually very low pitched, is sometimes called creaky voice, or vocal fry. It is used to make contrasts between consonants in several American Indian languages. An additional glottal state that is widely used--e.g., in the Austronesian (Malayo-Polynesian) languages of the Philippines--is a glottal stop, a tight closure of the two vocal cords. This articulation also occurs in many forms of English as the usual pronunciation of t in words such as bitten and fatten.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
In English, all sounds are produced with an airstream caused by the expiration of the air from the lungs. This is known as a pulmonic airstream. Other mechanisms for producing an airstream also occur. If there is a glottal stop and the closed glottis is moved rapidly upward or downward it can act like a piston pushing or pulling the air in the pharynx. This is the glottalic airstream mechanism. When there is an upward movement of the closed glottis the resulting sound is called an ejective. Amharic, the national language of Ethiopia, uses this mechanism to produce both ejective stops and fricatives, which contrast with the more usual stops and fricatives made with a pulmonic airstream mechanism. A downward movement of the glottis is used in the production of implosive sounds, which occur in many American Indian, African, and other languages. The use of movements of the tongue to suck air into the mouth is known as the velaric airstream mechanism; it occurs in the production of clicks, which are regular speech sounds in many languages of southern Africa.
To summarize, a consonant may be described by reference to seven factors: (1) state of the glottis, (2) secondary articulation (if any), (3) place of articulation, (4) type of airstream, (5) central or lateral articulation, (6) velic closure--oral or nasal, and (7) manner of articulation. Thus the consonant at the beginning of the word swim is a (1) voiceless, (2) labialized, (3) alveolar, (4) pulmonic, (5) central, (6) oral, (7) fricative. Unless a specific statement is made to the contrary, consonants are usually presumed to have a pulmonic airstream and no secondary articulation, and it is also assumed that they are not laterals or nasals. Consequently, points 2, 4, 5, and 6 are often disregarded and a three-term description--e.g., voiceless alveolar fricative is sufficient.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Vowels traditionally have been specified in terms of the position of the highest point of the tongue and the position of the lips. Figure 2

Tongue position for several vowel sounds.shows these positions for eight different vowels. The highest point of the tongue is in the front of the mouth for the vowels in heed, hid, head, and had. Accordingly, these vowels are classified as front vowels, whereas the vowels in hod, hawed, hood, and who'd are classified as back vowels. The tongue is highest in the vowels in heed and who'd, which are therefore called high, or close, vowels, and lowest in the vowels in had and hod, which are called low, or open, vowels. The height of the tongue for the vowels in the other words is between these two extremes, and they are therefore called midvowels. Lip positions may be described as being rounded, as in who'd, or unrounded or spread, as in heed.
The specification of vowels in terms of the position of the highest point of the tongue is not entirely satisfactory for a number of reasons. In the first place, it disregards the fact that the shape of the tongue as a whole is very different in front vowels and in back vowels. Second, although the height of the tongue in front vowels varies by approximately equal amounts for what are called equidistant steps in vowel quality, this is just not factually true in descriptions of back vowels. Third, the width of the pharynx varies considerably, and to some extent independently of the height of the tongue, in different vowels.
Some authorities use terms such as tense and lax to describe the degree of tension in the tongue muscles, particularly those muscles responsible for the bunching up of the tongue lengthways. Other authorities use the term tense to specify a greater degree of muscular activity, resulting in a greater deformation of the tongue from its neutral position. Tense vowels are longer than the corresponding lax vowels. The vowels in heed and hayed are tense, whereas those in hid and head are lax.
In many languages there is a strong tendency for front vowels to have spread lip positions, and back vowels to have lip rounding. As will be seen in the next section, this results in vowels that are acoustically maximally distinct. But many languages--e.g., French and German--have front rounded vowels. Thus French has a contrast between a high front unrounded vowel in vie, "life," and a high front rounded vowel with a very similar tongue position in vu, "seen," as well as a high back rounded vowel in vous, "you." Unrounded back vowels also occur--e.g., in Vietnamese.
Nasalized vowels, in which the soft palate is lowered so that part of the airstream goes out through the nose, occur in many languages. French distinguishes between several nasalized vowels and vowels made with similar tongue positions but with the soft palate raised. Low vowels in many forms of English are often nasalized, especially when they occur between nasal consonants, as in man.
Because of the difficulty of observing the precise tongue positions that occur in vowels, a set of eight vowels known as the cardinal vowels has been devised to act as reference points. This set of vowels is defined partly in articulatory and partly in auditory terms. Cardinal vowel number one is defined as the highest and farthest front tongue position that can be made without producing a fricative sound; cardinal vowel number five is defined as the lowest and farthest back vowel. Cardinal vowels two, three, and four are a series of front vowels that form auditorily equidistant steps between cardinal vowels one and five; and cardinal vowels six, seven, and eight are a series of back vowels with the same sized auditory steps as in the front vowel series. Phoneticians who have been trained in the cardinal vowel system are able to make precise descriptions of the vowels of any language in terms of these reference points.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Vowels and consonants can be considered to be the segments of which speech is composed. Together they form syllables, which in turn make up utterances. Superimposed on the syllables there are other features that are known as suprasegmentals. These include variations in stress (accent) and pitch (tone and intonation). Variations in length are also usually considered to be suprasegmental features, although they can affect single segments as well as whole syllables. All of the suprasegmental features are characterized by the fact that they must be described in relation to other items in the same utterance. It is the relative values of the pitch, length, or degree of stress of an item that are significant. The absolute values are never linguistically important, although they may be of importance paralinguistically, in that they convey information about the age and sex of the speaker, his emotional state, and his attitude.
Many languages--e.g., Finnish and Estonian--use length distinctions, so that they have long and short vowels; a slightly smaller number of languages, among them Luganda (the language spoken by the largest tribe in Uganda) and Japanese, also have long and short consonants. In most languages segments followed by voiced consonants are longer than those followed by voiceless consonants. Thus the vowel in cad before the voiced d is much longer than that in cat before the voiceless t. Variations in stress are caused by an increase in the activity of the respiratory muscles, so that a greater amount of air is pushed out of the lungs, and in the activity of the laryngeal muscles, resulting in significant changes in pitch. In English, stress has a grammatical function, distinguishing between nouns and verbs, such as an insult versus to insult. It can also be used for contrastive emphasis, as in I want a RED pen, not a black one.
Variations in laryngeal activity can occur independently of stress changes. The resulting pitch changes can affect the meaning of the sentence as a whole, or the meaning of the individual words. Pitch pattern is known as intonation. In English the meaning of a sentence such as That's a cat can be changed from a statement to a question by the substitution of a mainly rising for a mainly falling intonation. Pitch patterns that affect the meanings of individual words are known as tones and are common in many languages. In Chinese, for example, a syllable that is transliterated as ma means "mother" when said on a high tone, "hemp" on a midrising tone, "horse" on the falling-rising tone, and "scold" on a high-falling tone.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Speech sounds consist of small variations in air pressure that can be sensed by the ear. Like other sounds, speech sounds can be divided into two major classes--those that have periodic wave forms (i.e., regular fluctuations in air pressure) and those that do not. The first class consists of all the voiced sounds, because the vibrations of the vocal cords produce regular pulses of air pressure.
From a listener's point of view, sounds may be said to vary in pitch, loudness, and quality. The pitch of a sound with a periodic wave form--i.e., a voiced sound--is determined by its fundamental frequency, or rate of repetition of the cycles of air pressure. For a speaker with a bass voice, the fundamental frequency will probably be between 75 and 150 cycles per second. Cycles per second are also called hertz (Hz); this is the standard term for the unit in frequency measurements. A soprano may have a speaking voice in which the vocal cords vibrate to produce a fundamental frequency of over 400 hertz. The relative loudness of a voiced sound is largely dependent on the amplitude of the pulses of air pressure produced by the vibrating vocal cords. Pulses of air with a larger amplitude have a larger increase in air pressure.
The quality of a sound is determined by the smaller variations in air pressure that are superimposed on the major variations that recur at the fundamental frequency. These smaller variations in air pressure correspond to the overtones that occur above the fundamental frequency. Each time the vocal cords open and close there is a pulse of air from the lungs. These pulses act like sharp taps on the air in the vocal tract, which is accordingly set into vibration in a way that is determined by its size and shape. In a vowel sound, the air in the vocal tract vibrates at three or four frequencies simultaneously. These frequencies are the resonant frequencies of that particular vocal tract shape. Irrespective of the fundamental frequency that is determined by the rate of vibration of the vocal cords, the air in the vocal tract will resonate at these three or four overtone frequencies as long as the position of the vocal organs remains the same. In this way a vowel has its own characteristic auditory quality, which is the result of the specific variations in air pressure caused by the superimposing of the vocal tract shape on the fundamental frequency produced by the vocal cords.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The resonant frequencies of the vocal tract are known as the formants. The frequencies of the first three formants of the vowels in the words heed, hid, head, had, hod, hawed, hood, and who'd are shown in Figure 3

Schematic spectrogram showing frequencies of the first three formants of the vowels in.... Comparison with Figure 2 Figure 2: Tongue position for several vowel sounds.shows that there are no simple relationships between actual tongue positions and formant frequencies. There is, however, a good inverse correlation between one of the labels used to describe the tongue position and the frequency of the first, or lowest, formant. This formant is lowest in the so-called high vowels, and highest in the so-called low vowels. When phoneticians describe vowels as high or low, they probably are actually specifying the inverse of the frequency of the first formant.
Most people cannot hear the pitches of the individual formants in normal speech. In whispered speech, however, there are no regular variations in air pressure produced by the vocal cords, and the higher resonances of the vocal tract are more clearly audible. It is quite easy to hear the falling pitch of the second formant when whispering the series of words heed, hid, head, had, hod, hawed, hood, who'd. Conversely, the auditory effect of the second and higher formants is lessened when speaking in a creaky voice. Under such conditions, it is possible to hear the rise in pitch of the first formant during the first four of these words, and the fall in pitch during the last.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Voiced consonants such as nasals and laterals also have specific vocal tract shapes that are characterized by the frequencies of the formants. They differ from vowels in that in their production the vocal tract is not a single tube. There is a side branch formed when the nasal tract is coupled in with the oral tract, or, in the case of laterals, when the oral tract itself is obstructed in the centre. The effect of these side branches is that the relative amplitudes of the formants are altered; it is as if one or more of the possible superimposed variations in air pressure had been lessened because it had been trapped in the cavity formed at the side. Nasals and laterals can therefore be specified in terms of their formant frequencies, just like vowels. But in a complete specification of these consonants the relative amplitudes of the formants also have to be given, because they are not completely predictable.
Other voiced consonants such as stops and approximants (semivowels) are more like vowels in that they can be characterized in part by the resonant frequencies--the formants--of their vocal tract shapes. They differ from vowels in that during a voiced stop closure there is very little acoustic energy, and during the release phase of a stop and the entire articulation of a semivowel the vocal tract shapes are changing comparatively rapidly. These transitional movements can be specified acoustically in terms of the movements of the formant frequencies.
Voiceless sounds do not have a periodic wave form with a well-defined fundamental frequency. Nevertheless, some sensations of pitch accompany the variations in air pressure caused by the turbulent airflow that occurs during a voiceless fricative, or in the release phase of a voiceless stop. This is because the pressure variations are far from random. During the first consonant in sea these have a tendency to be at a higher centre frequency, and hence a higher pitch, than in the pronunciation of the first consonant in she. There is also a difference in the average amplitude of the wave form in different voiceless sounds. All voiceless sounds have much less energy--i.e., a smaller amplitude--than voiced sounds pronounced with the same degree of effort. Other things being equal, the fricatives in sin and shin have more amplitude--i.e., are louder--than those in thin and fin.
In summary, speech sounds are fairly well defined by nine acoustic factors. The first three factors include the frequencies of the first three formants; these are responsible for the major part of the information in speech. Characterizing the vocal tract shape, these formant frequencies specify vowels, nasals, laterals, and the transitional movements in voiced consonants. The frequencies of the fourth and higher formants do not vary significantly. The fourth factor is the fundamental frequency--roughly speaking, the pitch--of the larynx pulse in voiced sounds, and the fifth, the amplitude--roughly speaking, the loudness--of the larynx pulse. These last two factors account for suprasegmental information; e.g., variations in stress and intonation. They also distinguish between voiced and voiceless sounds, in that the latter have no larynx pulse amplitude. The centre frequency of the high-frequency hissing noises in voiceless sounds constitutes the sixth acoustic factor, and the seventh is the amplitude of these high-frequency noises. These two factors characterize the major differences among voiceless sounds. In more accurate descriptions it would be necessary to specify more than just the centre frequency of the noise in fricative sounds. The eighth and ninth factors include the amplitudes of the second and third formants relative to the first formant; the amplitudes of the formants as a whole are determined by the larynx pulse amplitude. These latter factors are the least important in that they convey only supplementary information about nasals and laterals.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Instruments for acoustic phonetics
The principal instrument used in acoustic phonetic studies is the sound spectrograph. This device gives a visible record of any kind of sound. In a spectrographic analysis of the phrase speech pictures, time of occurrence of each item is given on the horizontal scale. The vertical scale shows the frequency components at each moment in time, the amplitude of the components being shown by the darkness of the mark. (Figure 3
Schematic spectrogram showing frequencies of the first three formants of the vowels in...diagrams the formant frequencies in a set of English vowels in the same way and might be regarded as a schematic spectrogram.) In the phrase speech pictures the first consonant has a comparatively random distribution of energy, but it is mainly in the higher frequencies. The second consonant is a voiceless stop, which produces a short gap in the pattern. The next segment, the first vowel, has four formants that appear as dark bars with centre frequencies of 300, 2,000, 2,700, and 3,400 hertz. Each of the other segments has its own distinctive pattern.
Much information has also been gained from the use of speech synthesizers, which are instruments that take specifications of speech in terms of the acoustic factors summarized above and generate the corresponding sounds. Some speech synthesizers use electronic signal generators and amplifiers; others use digital computers to calculate the values of the required sound waves. Good synthetic speech is hard to distinguish from high-quality recordings of natural speech. The principal value of a speech synthesizer is its precisely controllable "voice" that an experimenter can vary in a systematic way to determine the perceptual effects of different acoustic specifications.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Phonetics is part of linguistics in that one of the main aims of phonetics is to determine the categories that can be used in explanatory description of languages. One way of looking at the grammar of a language is to consider it to be a set of statements that explains the relation between the meanings of all possible sentences in a language and the sounds of which they are composed. In this view, a grammar may be divided into three parts: the syntactic component, which is a set of rules describing the ways in which words may form sentences; the lexicon, which is a list of all the words and the categories to which they belong; and the phonological component, which is a set of rules that relates phonetic descriptions of sentences to the syntactic and lexical descriptions.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
In the lexicon of a language, each word is represented in its underlying, or basic, form, which discounts all of the alternations in pronunciation that are predictable by phonological rules. For example, there are phonological rules that will account for the variations in the placement of stress and the alternations of vowel quality that occur in sets of words such as harmOny, harmOnic, harmOnious and melOdy, melOdic, melOdious. The rules that predict the pronunciation of the capitalized O's are general, rather than specific for each word, and the grammar should state such rules so that the regularities are revealed. Accordingly, each of these words must be entered in the lexicon in a way that represents simply its underlying form, and that allows the alternations that occur to be generated by phonological rules. The underlying form is known as the phonemic--sometimes morphophonemic, or phonological--representation of the word. The phonemes of a language are the segments that contrast in the underlying forms. American English may be said to have at least 13 vowel phonemes, which contrast in the underlying forms of words such as bate, bat, beat, bet, bite, bit, bout, but, boat, dot, bought, balm, and boy. Some authorities consider that there are additional vowel phonemes exemplified in the words bush and beaut(y), but others believe that these can be derived from the same underlying vowel as that in the word bud. Phonemes are traditionally written between slanting lines, as /P/, /M/, or /L/.
The variants of phonemes that occur in phonetic representations of sentences are known as allophones. They may be considered to be generated as a result of applying the phonological rules to the phonemes in underlying forms. For example, there is a phonological rule of English that says that a voiceless stop such as /P/ is aspirated when it occurs at the beginning of a word (e.g., in pin), but when it occurs after a voiceless alveolar fricative (i.e., after /S/), it is unaspirated (e.g., in spin). Thus the underlying phoneme /P/ has an aspirated and an unaspirated allophone, in addition to other allophones that are generated as a result of other rules that apply in other circumstances. Allophones are conventionally written inside brackets--e.g., [p] or aspirated [ph].
In stating phonological rules it is necessary to refer to classes of phonemes. Consider part of the rule for the formation of the plural in English: there is an extra vowel in the suffix if the word ends in the same sound as occurs at the end of horse, maze, fish, rouge, church, or judge. The plural forms of words of this kind are one syllable longer than the singular forms. The phonological rules of English could simply list the phonemes that behave in the same way in the rules for plural formation; the rules for the possessive forms of nouns and for the 3rd person singular of the present tense of verbs are similar in this respect. The rules are more explanatory, however, if they show that these phonemes behave in a similar way because they form a natural class, or set, whose members are defined by a common property. In the case of these plural forms, the phonemes are all, and only, those that have a high-frequency fricative component; they may be called the sibilant, or strident, phonemes.
Other phonological rules that refer to the natural classes of phonemes have already been mentioned. The rule concerning voiceless stops' being aspirated in some circumstances and unaspirated in others refers to the subset of phonemes that are both voiceless sounds and stops. Similarly, the variations in vowel length in cat and cad can be expressed with reference to the set of phonemes that are vowels, and also to the set that comprises both voiceless sounds and stops.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Each of the phonemes that appears in the lexicon of a language may be classified in terms of a set of phonetic properties, or features. Phoneticians and linguists have been trying to develop a set of features that is sufficient to classify the phonemes in each of the languages of the world. A set of features of this kind would constitute the phonetic capabilities of man. To be descriptively adequate from a linguistic point of view, the set of features must be able to provide a different representation for each of the words that is phonologically distinct in a language; and if the feature set is to have any explanatory power it must also be able to classify phonemes into appropriate natural classes as required in the phonological rules of each language.
In the earlier work on feature sets, emphasis was placed on the fact that features were the smallest discrete components of language. Not much attention was paid to their role in classifying phonemes into the natural classes required in phonological rules. Instead, they were considered to be the units to which a listener attends when listening to speech. Features were justified by reference to their role in distinguishing phonemes in minimal sets of words such as bill, pill, fill, mill, dill, sill, kill.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Jakobson, Fant, and Halle features
As a result of studying the phonemic contrasts within a number of languages, Roman Jakobson, Gunnar Fant, and Morris Halle concluded in 1951 that segmental phonemes could be characterized in terms of 12 distinctive features. All of the features were binary, in the sense that a phoneme either had, or did not have, the phonetic attributes of the feature. Thus phonemes could be classified as being consonantal or not, voiced or not, nasal or not, and so on. In 1968, Noam Chomsky and Morris Halle stated that nearer 30 features are needed for a proper description of the phonetic, and linguistic, capabilities of man. In agreement with Jakobson, they claimed that each feature functions as a binary opposition that can be given the value of plus or minus in classifying the phonemes in underlying forms. But they suggested that the features may require more precise systematic phonetic specifications.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Some of the binary features proposed by Chomsky and Halle are listed in Table 1. The first group comprises major class features, because these features are required for dividing sounds into classes such as vowels, consonants, and semivowels. There are several problems in giving satisfactory definitions of the phonetic properties of these features, but there is no doubt that binary oppositions of this kind are needed for describing phonological patterns.
The next group, the manner of articulation features, includes continuant/noncontinuant (in which noncontinuant is exactly equivalent to the notion of stop as defined above), and delayed release (the comparatively slow parting of the articulators that occurs in an affricate). The source features refer to the action of the vocal cords (voice) or to fricative noise mechanisms (strident).
The cavity features include nasal and lateral, which are used in the same sense as they were in the section on articulatory phonetics, and the features that determine the place of articulation of consonants and the quality of vowels. The most important features specifying the place of articulation of consonants are anterior, made in the front of the mouth, and coronal, made with the tip or blade of the tongue raised toward the teeth or teeth ridge. These two features can be used to specify four places of articulation: bilabial (+anterior, -coronal); dental, or alveolar (+anterior, +coronal); postalveolar, or palato-alveolar (-anterior, +coronal); velar (-anterior, -coronal). There is still some disagreement concerning whether consonantal places of articulation are specified appropriately by binary oppositions of this kind.
There is even more disagreement over the advisability of describing vowels in terms of binary features. Chomsky and Halle use the features high/nonhigh and low/nonlow to specify the height of the tongue, midtongue positions being considered to be simply those that are -high, -low; the feature back/nonback is employed to specify the front/back distinctions among vowels. But these three features can be combined to specify only six basic tongue positions: high front, high back, midfront, midback, low front, and low back. It is true that each of these possibilities can have tense/nontense (lax) variants and rounded/nonrounded (spread) variants. But the Chomsky-Halle feature system does not permit the specification within underlying forms of central vowels, nor of more than three degrees of tongue height. Moreover, their binary oppositions of vowel height do not make it clear that the difference between low vowels and midvowels is the same as that between midvowels and high vowels.
Table 2 shows the feature composition of a number of segments that occur in English. The phonetic symbols at the top of each column are used with the values discussed in the following section.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Table 1: Part of the Set of Features Proposed by Chomsky and Halle (1968)
| Major class features | Cavity features |
| consonantal | nasal |
| syllabic | lateral |
| sonorant | . |
| . | anterior |
| Manner of articulation features | coronal |
| continuant | . |
| delayed release | high |
| tense | low |
| . | back |
| Source features | . |
| voice | round |
| strident | . |

There are many different kinds of phonetic transcription. In some circumstances a phonetic symbol can be simply an abbreviation for a phonetic description. The symbol [s] may then be regarded as exactly equivalent to the phrase "voiceless, alveolar, fricative." When a linguist tries to describe an unknown language he begins by writing it down using symbols in this way. Later, when he has learned about the function of sounds and the underlying forms in the language, he might make a more systematic transcription, known as a broad transcription, in which each phoneme is represented by a simple symbol.
Occasionally it is convenient to use a transcription in which some of the allophones are represented by specific symbols, or some of the phonemes are designated by the symbols for a more restricted set of categories. If, for example, the transcription were to be used in teaching pronunciation, the difference between the aspirated and unaspirated allophones of /P/ might be represented by transcribing pan as [phan] and span as [span]; or the vowel phoneme in each of these words might be designated by the more specific symbol [?], which represents a low front vowel of a certain type. In a narrow transcription the symbols are more specific, either because allophones are differentiated, or because the phonetic quality of the sounds is shown more precisely.
The most widely used set of symbols is that of the International Phonetic Association (IPA). In general, the consonants have the same values as the corresponding letters in many European languages; the vowel symbols have similar values to the corresponding letters in a language such as Italian.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Experimental phonetics employs the methods of investigation commonly used in other disciplines--e.g., physics, physiology, and psychology--for measuring the physical and physiological dimensions of speech sounds and their perceptual characteristics. The sound spectrograph and speech synthesizers were mentioned in the section on acoustic phonetics. Other techniques include the use of X-rays; air-pressure and air-flow recording; palatography, a method of registering the contacts between the tongue and the roof of the mouth; and cinematography. All of these techniques have been used for studying the actions of the vocal organs.
Much of the work in experimental phonetics has been directed toward obtaining more accurate descriptions of the sounds that characterize different languages. There have also been several studies aimed at determining the relative importance of different features in signalling contrasts between sounds. But experimental phoneticians are probably most concerned with trying to discover the central cerebral processes involved in speech.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
One issue of this kind that has been extensively discussed is the so-called motor theory of speech perception. There is a great deal of evidence that the way in which people speak greatly influences their perception of what is said to them. For example, speakers of Spanish cannot pronounce the different vowels in words such as ship and sheep in English. These people also have difficulty in hearing the difference between these two vowels. But when they have learned, by trial and error methods, to say them correctly, then they can easily hear the difference. Similarly, using synthetic speech stimuli it is possible to make a series of consonant sounds that go by acoustically equidistant steps from [b] through [d] to [g]. When listeners hear these synthetic sounds they do not consider the steps between them to be auditorily equidistant. The steps that correspond to the large articulatory movements between the consonants are heard as being much larger than the equal size acoustic steps that do not correspond to articulatory movements occurring in the listener's speech. Facts such as these have led some phoneticians to believe that the perception of speech is structured more in motor--articulatory--terms than in acoustic terms. Other phoneticians have claimed that the evidence does not really distinguish between these two possibilities but demonstrates simply that the perception of speech is structured in terms of linguistic categories.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Another major problem is the size of the units that are involved in the perception of speech. Some authorities have claimed that a listener distinguishes between words by making a series of binary decisions concerning the features in each segment that he hears. Others hold that the listener takes in information in much larger temporal pieces and perhaps processes speech in terms of units of at least the size of a syllable. All authorities agree on the importance of context in the processing of information. Speech conveys information in a redundant way. Experiments have shown that a listener need attend to only a part of the information presented to him in order to understand all that is being said.
A related problem is that of the temporal structure of speech production. There may be very little structure, and a speaker may simply time the movements of his vocal organs by allowing each gesture to run its course before starting on the next one. Alternatively, he may impose a hierarchical structure on the gestures by requiring, for instance, each major stress in a sentence to occur at some predetermined moment, and the articulatory movements to be speeded up or slowed down depending on the number of movements that have to occur before the major stress. There is some evidence in favour of this latter possibility as a result of experiments in which a speaker is asked to say a given phrase first slowly and then fast. When he is speaking at a rate that is twice as fast as some other rate, then the interval between the major stresses is about halved. But the duration of each segment is not halved. The consonants are only slightly reduced in length, whereas the vowels are considerably shortened. Some authorities have used the results of experiments of this kind to argue that the stress group is the major unit in the temporal organization of speech.
(P.N.L./Ed.)
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
D. Abercrombie, Elements of General Phonetics (1967), a readable survey of selected topics; P. Ladefoged, A Course in Phonetics (1975), a foundation in linguistic phonetics; K.L. Pike, Phonetics (1943), and P. Ladefoged, Preliminaries to Linguistic Phonetics (1971), critical analyses of phonetic theory; R. Jakobson, C.G.M. Fant, and M. Halle, Preliminaries to Speech Analysis (1952), the first major account of distinctive feature theory; N. Chomsky and M. Halle, The Sound Pattern of English (1968), a comprehensive description of English phonology; P. Ladefoged, Elements of Acoustic Phonetics (1962), an introduction to the physics of speech; I. Lehiste (comp.), Readings in Acoustic Phonetics (1967), a collection of major articles; B. Malmberg (ed.), Manual of Phonetics (1968), authoritative chapters on many aspects of phonetics. Acoustic aspects of speech production are also treated in Dennis B. Fry, The Physics of Speech (1979); J.M. Pickett, The Sounds of Speech Communication (1980); Richard M. Warren, Auditory Perception (1982). David Chrystal, A First Dictionary of Linguistics and Phonetics (1981), covers main topics in articulatory and acoustic phonetics. See also recent issues of these journals: American Speech and Hearing Association (ASHA) Journal (monthly); and Journal of Speech and Hearing Research (quarterly).
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.