
AACAADAACDAAABCBDBBCDC
Если вероятность появления любого символа в тексте равна еденице, то тут как вы понимаете вероятности появления символов такие:
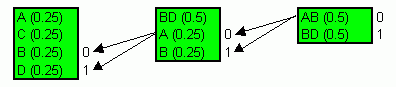
Далее мы должны работать со списком, где символы отсортированны по убыванию вероятности. Наши действия просты, мы берем два символа в наименьшей вероятностью (два самых редких), здесь это B,D. Складываем их вероятности и получаем вероятность появления в тексте символа B или D. Заменяем эти символы одним абстрактным символом BD с вероятностью 0.35. Потом делаем тоже самое по кругу, пока все символы не кончатся. И в списке не останется общий символ с вероятностью 1.
Надеюсь вы понимаете, что на практике тоже самое делают со цельночисленными счётчиками числа символов, а не вероятностями.

Теперь код которым кодируется каждый символ можно получить просто пройдя в обратном порядке и запомнив путь. А данном случае символы мы кодировать будем так:
1 1 01 1 1 001 1 1 01 001 1 1 1 000 01 000 001 000 000 01 001 01Что равняется 43 битам или 6 байтам. Вместо 21 байта.
Пример конешно игрушечный, но метод работает хорошо. Такие вещи как Хаффман и Арифметическое кодирование в статическом режиме не приводят к увеличению размера кодируемых данных. Т.е. в теории и на практике, если вы сожмёте любые данные, то они будут либо меньше либо (худшем случае) размер будет таким же.
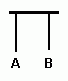
Применение фиксированой таблицы в данном случае будет ошибкой, потому как созданное дерево может иметь разную форму. Если все символы равновероятны, то коды будут иметь вид тупой таблицы из кодов с одинаковой разрядностью. А кодирование будет оставлять данные без изменения. Приблизительно так:
Адаптивный метод не гарантирует уменьшение размеров данных в любом случае. Т.е. данные после упаковки могут вырасти. Но практике применяется именно адаптивный метод (как и в большинстве алгоритмов упаковки). Потому как в нём не нужно прилагать к упакованым байтам таблицу и он очень часто обгоняет статический метод по силе сжатия.
Встречая первые два символа (A) мы ничего не делаем. Встречая символ C мы поднимаем его на одну позицию вверх (меняем просто два соседних местами).
В итоге после кодирования вероятности будут расположены так:
А наша строка будет закодирована как
1 1 000 1 1 001 1 1 01 000 000 01 1 001 01 000 001 01 1 01 000 1
Что есть 43 бита, но теже 6 байт.
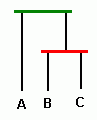
 если в данном узле счётчики A>B , то меняем местами ветки A и B.
если в данном узле счётчики A>B , то меняем местами ветки A и B.
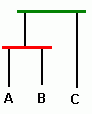
 очевидно что после первого преобразования B≤C и A≤(B+C).
очевидно что после первого преобразования B≤C и A≤(B+C).
 .
.
В самом начале работы, я создаю полностью сбалансированное дерево из всех символов, но каждый счётчик имеет нулевое значение. Таким образом любой реальный символ текста автоматически перевешивает всё это нулевое дерево, обеспечивая для себя минимальный код. Но в тоже время сохраняется возможность добавлять другие реальные символы в дерево, без больших затрат.
В реальных условиях это не самая лучшая модель. Она довольно медленно адаптируется к потоку символов. Необходимо как-то ослаблять влияние старых символов на дерево. Например время от времени можно делить все счётчики дерева пополам. Сжатие таким образом может работать немного лучше.
ACDCABEBDDCBEBACEBDEBИтак в начале каждому символу соотвествует некий список, единичной длины. (через двоеточие указана длина кода, через тире - частота использования).
Сами коды для хафмана очень легко получить имея только таблицу длин кодов.
void Gen(int len_array[],int codes[],int count)
{
int n,code=0,len=1;
for(n=0; n<count;) {
if(len_array[n]==len) codes[n++]=code++;
else code<<=1,len++;
}
}
|
Для того чтобы все коды удобным образом умещались в наши переменные, можно ограничить длину кодов 16-ю или 32-мя битами. Для этого надо просто перераспределить массу длин. Т.е. найти все кода которые больше 16 (или 32) и уменьшить их до 16 бит. Соотвествующим образом увеличив длины более коротких кодов, с тем чтобы сохранить общую сумму длин (увеличивать лучше длины самых редких кодов). Если длина файла не превышает 32 битного числа, то я плохо представляю что надо сделать для того чтобы один из кодов стал длинее 32 бит.
Самый интересный момент заключается в способе сохранения наших кодов в файле. Если мы упаковывали 8-битные данные и ограничивали длину кодов 16-ю битами. То на диск достаточно сохранить 16 байтов, для описания длин. Каждый из которых указывает сколько соотвествующих длин кодов есть в таблицах, в следов сохранить 256 символов отсортированных в по частоте использования (если не все коды используются, то сохранять можно меньше). Для восстановления информации о кодах всего этого будет достаточно. В случае нашей строки это будет выглядеть так. Коды еденичной длины мы не используем, у нас есть три кода длиной в два бита, и два кода длиной в три бита. Значит таблица длин и символов будет выглядеть так:
0 3 2 0 .... 0 |
Кстати говоря, вовсе не обязательно во время слияния списков помнить длину кода каждого элемента. Можно сразу вычислять общее количество длин в кодов. Для этого достаточно завести битовую маску в заголовке каждого списка, которая указывает какой длины коды есть в самом списке.