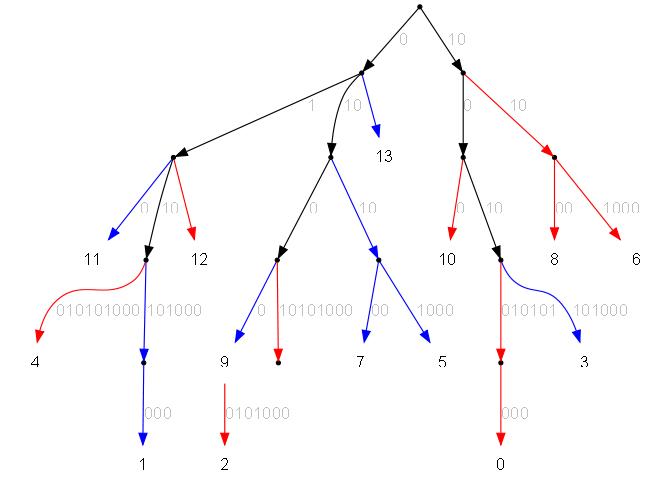
Строка разбивается на пары: 12 11 12 21 22 21
Пары сортирутся:11 12 12 21 21 22.
Удаляются копии: 11 12 21 22.
Парам даются номера (условно, в массиве они и так есть): 11 (0) 12 (1) 21 (2) 22 (3)
Создаётся новая строка из номеров пар: 1 0 1 2 3 2
Из полученной строки создаётся суффикcное дерево:
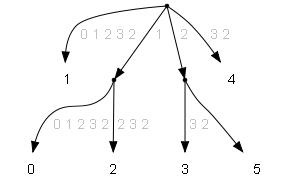
Суффиксный массив новой строки:
| ID | LCP | str |
| 1 | 0 | 0 1 2 3 2 |
| 0 | 0 | 1 0 1 2 3 2 |
| 2 | 1 | 1 2 3 2 |
| 3 | 0 | 2 3 2 |
| 5 | 1 | 2 |
| 4 | 0 | 3 2 |
В принципе можно просто задать номера уникальным парам не прибегая с сортировке, но это создаст дополнительные проблемы в работе.
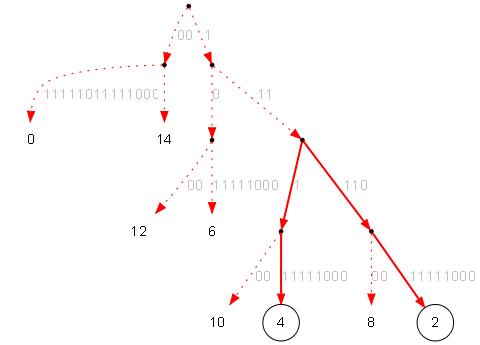
Из дерева сжатой строки получаем частичное (чётное) дерево исходной строки. Частичное потому в нём будут только половина суффиксов, т.е. тех которые стоят в чётных позициях. Очевидно что для этого достаточно умножить все расстояния в дереве на 2:
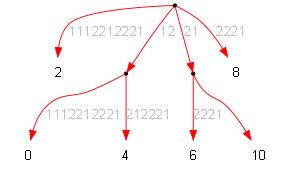
Корректируются все развилки дерева (так как они могут совпадать в первых символах):
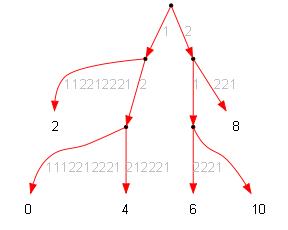
Суффиксный массив чётного дерева исходной строки:
| ID | LCP | str |
| 2 | 0 | 1112212221 |
| 0 | 1 | 121112212221 |
| 4 | 2 | 12212221 |
| 6 | 0 | 212221 |
| 10 | 2 | 21 |
| 8 | 1 | 2221 |
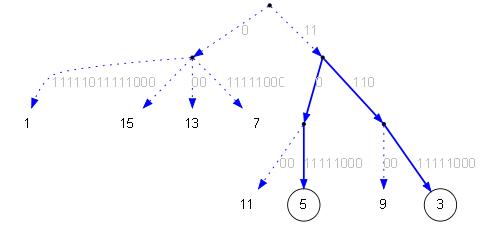
Из чётного дерева, нужно получить нечётное дерево (дерево из суффиксов в нечётных позициях). Для этого можно взять суффиксный массив чётного дерева, отрезать первые символы, и выполнить стабильную сортировку по оставшимся первым символам:
Суффиксный массив нечётного дерева исходной строки:
| ID | LCP | str |
| 3 | 0 | 112212221 |
| 7 | 1 | 12221 |
| 11 | 1 | 1 |
| 1 | 0 | 21112212221 |
| 5 | 1 | 2212221 |
| 9 | 3 | 221 |
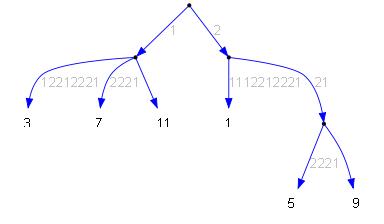
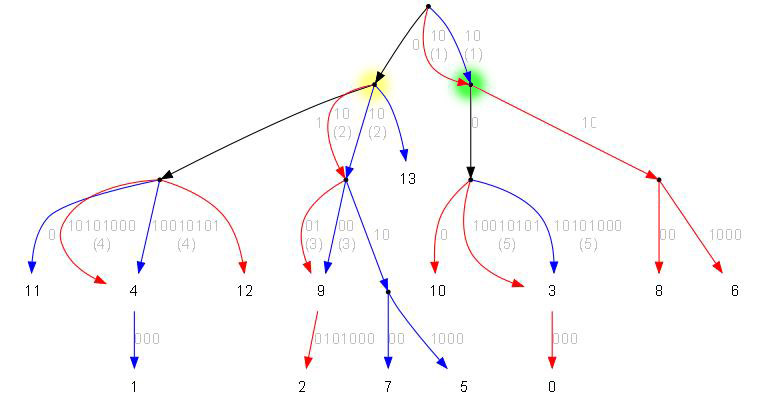
Выполняется слияние. Для этого мы просто рекурсивно проходим дуги обоих деревьев, но сравниваем только первые символы дуг. Если в двух деревьях попадаются дуги разной длины, то длину эту грубо подгоняем, например лепим на более длинную ещё один узел (думаю так всё очевидно). Если попадаются две дуги с одинаковыми начальными символами, то обе заносятся в результат:
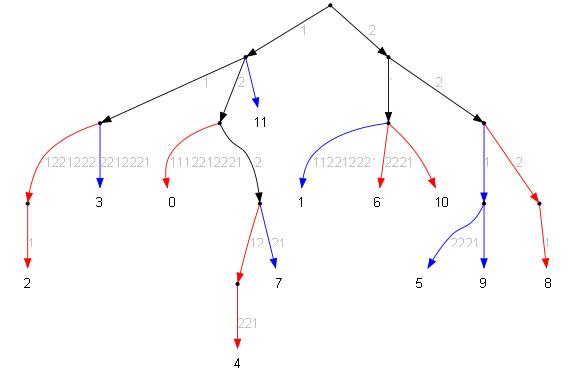
Слитое дерево (условно):
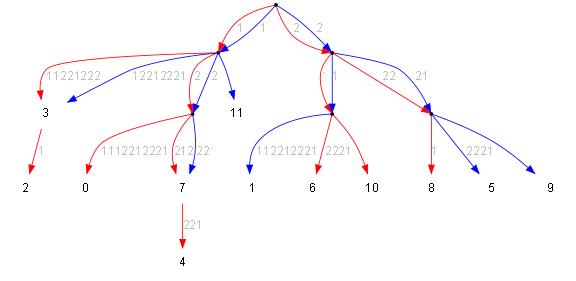
Слитое дерево (в упрощённом виде):
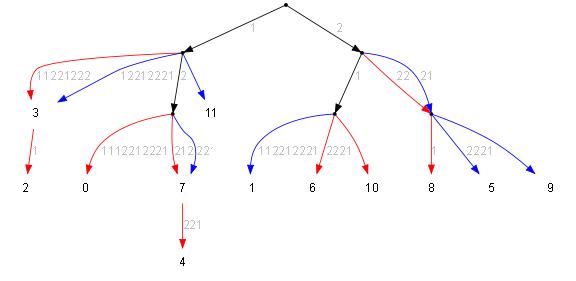
Разбираемся с двойными дугами (на этом примере из три). Для этого мы должны выяснить сколько начальных символов таких дуг совпадает. Если дуги совпадают полностью, тогда ничего не делаем, удаляем одну из копий и всё. Если начало для двух дуг совпадает только частично, тогда нужно делать для них общее начало, а ветки которые на концах снова развести по разным деревъям (для этого можно во время снияния запомнить их начальный цвет или просто сохранить ссылки на исходные ветки).