the acquisition, recording, organization, retrieval, display, and dissemination of information. In recent years, the term has often been applied to computer-based operations specifically. In popular usage, the term information refers to facts and opinions provided and received during the course of daily life: one obtains information directly from other living beings, from mass media, from electronic data banks, and from all sorts of observable phenomena in the surrounding environment. A person using such facts and opinions generates more information, some of which is communicated to others during discourse, by instructions, in letters and documents, and through other media. Information organized according to some logical relationships is referred to as a body of knowledge, to be acquired by systematic exposure or study. Application of knowledge (or skills) yields expertise, and additional analytical or experiential insights are said to constitute instances of wisdom. Use of the term information is not restricted exclusively to its communication via natural language. Information is also registered and communicated through art and by facial expressions and gestures or by such other physical responses as shivering. Moreover, every living entity is endowed with information in the form of a genetic code. These information phenomena permeate the physical and mental world, and their variety is such that it has defied so far all attempts at a unified definition of information. Interest in information phenomena has increased dramatically in the 20th century, and today they are the objects of study in a number of disciplines, including philosophy, physics, biology, linguistics, information and computer science, electronic and communications engineering, management science, and the social sciences. On the commercial side, the information service industry has become one of the newer industries worldwide. Almost all other industries--manufacturing and service--are increasingly concerned with information and its handling. The different, though often overlapping, viewpoints and phenomena of these fields lead to different (and sometimes conflicting) concepts and "definitions" of information. This article touches on such concepts, particularly as they relate to information processing and information systems. In treating the basic elements of information processing, it distinguishes between information in analog and digital form, and it describes their acquisition, recording, organization, retrieval, display, and dissemination. In treating information systems, the article discusses system analysis and design and provides a descriptive taxonomy of the main system types. Some attention is also given to the social impact of information systems and to the field of information science.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Interest in how information is communicated and how its carriers convey meaning has occupied, since the time of pre-Socratic philosophers, the field of inquiry called semiotics, the study of signs and sign phenomena. Signs are the irreducible elements of communication and the carriers of meaning. The American philosopher, mathematician, and physicist Charles S. Peirce is credited with having pointed out the three dimensions of signs, which are concerned with, respectively, the body or medium of the sign, the object that the sign designates, and the interpretant or interpretation of the sign. Peirce recognized that the fundamental relations of information are essentially triadic; in contrast, all relations of the physical sciences are reducible to dyadic (binary) relations. Another American philosopher, Charles W. Morris, designated these three sign dimensions syntactic, semantic, and pragmatic, the names by which they are known today.
Information processes are executed by information processors. For a given information processor, whether physical or biological, a token is an object, devoid of meaning, that the processor recognizes as being totally different from other tokens. A group of such unique tokens recognized by a processor constitutes its basic "alphabet"; for example, the dot, dash, and space constitute the basic token alphabet of a Morse-code processor. Objects that carry meaning are represented by patterns of tokens called symbols. The latter combine to form symbolic expressions that constitute inputs to or outputs from information processes and are stored in the processor memory.
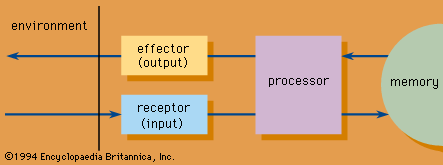
Information processors are components of an information system, which is a class of constructs. An abstract model of an information system features four basic elements: processor, memory, receptor, and effector (Figure 1)
Structure of an information system.). The processor has several functions: (1) to carry out elementary information processes on symbolic expressions, (2) to store temporarily in the processor's short-term memory the input and output expressions on which these processes operate and which they generate, (3) to schedule execution of these processes, and (4) to change this sequence of operations in accordance with the contents of the short-term memory. The memory stores symbolic expressions, including those that represent composite information processes, called programs. The two other components, the receptor and the effector, are input and output mechanisms whose functions are, respectively, to receive symbolic expressions or stimuli from the external environment for manipulation by the processor and to emit the processed structures back to the environment.
The power of this abstract model of an information-processing system is provided by the ability of its component processors to carry out a small number of elementary information processes: reading; comparing; creating, modifying, and naming; copying; storing; and writing. The model, which is representative of a broad variety of such systems, has been found useful to explicate man-made information systems implemented on sequential information processors.
Because it has been recognized that in nature information processes are not strictly sequential, increasing attention has been focused since 1980 on the study of the human brain as an information processor of the parallel type. The cognitive sciences, the interdisciplinary field that focuses on the study of the human mind, have contributed to the development of neurocomputers, a new class of parallel, distributed-information processors that mimic the functioning of the human brain, including its capabilities for self-organization and learning. So-called neural networks, which are mathematical models inspired by the neural circuit network of the human brain, are increasingly finding applications in areas such as pattern recognition, control of industrial processes, and finance, as well as in many research disciplines.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
In the late 20th century, information has acquired two major utilitarian connotations. On the one hand, it is considered an economic resource, somewhat on par with other resources such as labour, material, and capital. This view stems from evidence that the possession, manipulation, and use of information can increase the cost-effectiveness of many physical and cognitive processes. The rise in information-processing activities in industrial manufacturing as well as in human problem solving has been remarkable. Analysis of one of the three traditional divisions of the economy, the service sector, shows a sharp increase in information-intensive activities since the beginning of the 20th century. By 1975 these activities accounted for half of the labour force of the United States (see Table 1), giving rise to the so-called information society.
As an individual and societal resource, information has some interesting characteristics that separate it from the traditional notions of economic resources. Unlike other resources, information is expansive, with limits apparently imposed only by time and human cognitive capabilities. Its expansiveness is attributable to the following: (1) it is naturally diffusive; (2) it reproduces rather than being consumed through use; and (3) it can be shared only, not exchanged in transactions. At the same time, information is compressible, both syntactically and semantically. Coupled with its ability to be substituted for other economic resources, its transportability at very high speeds, and its ability to impart advantages to the holder of information, these characteristics are at the base of such societal industries as research, education, publishing, marketing, and even politics. Societal concern with the husbanding of information resources has extended from the traditional domain of libraries and archives to encompass organizational, institutional, and governmental information under the umbrella of information resource management.
The second perception of information is that it is an economic commodity, which helps to stimulate the worldwide growth of a new segment of national economies--the information service sector. Taking advantage of the properties of information and building on the perception of its individual and societal utility and value, this sector provides a broad range of information products and services. By 1992 the market share of the U.S. information service sector had grown to about $25 billion (see Table 2). This was equivalent to about one-seventh of the country's computer market, which, in turn, represented roughly 40 percent of the global market in computers in that year. However, the probable convergence of computers and television (which constitutes a market share 100 times larger than computers) and its impact on information services, entertainment, and education are likely to restructure the respective market shares of the information industry before the onset of the 21st century.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Table 1: Labour Distribution (%) in the United States, 1880-2000
| 1880 | 1920 | 1955 | 1975 | 2000 (est.) | |
| Agriculture and extractive | 50 | 28 | 14 | 4 | 2 |
| Manufacturing, commerce, industry | 36 | 53 | 37 | 29 | 22 |
| Information, knowledge, education | 2 | 9 | 29 | 50 | 66 |
| Other services | 12 | 10 | 20 | 17 | 10 |
Source: Adapted from Graham T.T. Molitor, "The Information Society: The Path to Post-Industrial Growth," Edward Cornish (ed.),Communications Tomorrow, The Coming of the Information Society, reprinted by permission of the World Future Society, Bethesda, Md.
Table 2: U.S. Information Services Market (in billions of dollars)
| 1989 | 1990 | 1991 | 1992* | 1993* | 1994* | |
| On-line transaction processing | 2.590 | 2.753 | 2.927 | 3.483 | 4.120 | 4.379 |
| Alarm monitoring/telemetry | 2.176 | 2.502 | 2.827 | 3.166 | 3.544 | 3.969 |
| Telemessaging services | 1.025 | 1.096 | 1.172 | 1.279 | 1.369 | 1.482 |
| Voice messaging | 0.157 | 0.220 | 0.282 | 0.367 | 0.489 | 0.666 |
| Electronic messaging | 0.464 | 0.580 | 0.737 | 0.958 | 1.274 | 1.707 |
| Database services | 8.587 | 9.675 | 10.916 | 12.336 | 13.962 | 15.829 |
| Residential data services | 0.235 | 0.272 | 0.319 | 0.373 | 0.434 | 0.505 |
| Voice information services | 0.726 | 1.048 | 1.342 | 1.609 | 1.879 | 2.113 |
| Enhanced facsimile | 0.020 | 0.045 | 0.059 | 0.078 | 0.104 | 0.135 |
| Electronic data exchange | 0.097 | 0.160 | 0.264 | 0.435 | 0.696 | 1.114 |
| Value-added network services | 0.724 | 0.790 | 0.861 | 0.935 | 1.018 | 1.104 |
| Business video services | 0.066 | 0.078 | 0.092 | 0.112 | 0.128 | 0.143 |
| Total | 16.867 | 19.219 | 21.798 | 25.131 | 29.017 | 33.146 |
*Projected as of 1991.
Source: Reprinted from Data Communications, Sept. 1991. Copyright 9/91 McGraw-Hill, Inc. All rights reserved.
Humans receive information with their senses: sounds through hearing; images and text through sight; shape, temperature, and affection through touch; and odours through smell. To interpret the signals received from the senses, humans have developed and learned complex systems of languages consisting of "alphabets" of symbols and stimuli and the associated rules of usage. This has enabled them to recognize the objects they see, understand the messages they read or hear, and comprehend the signs received through the tactile and olfactory senses.
The carriers of information-conveying signs received by the senses are energy phenomena--audio waves, light waves, and chemical and electrochemical stimuli. In engineering parlance, humans are receptors of analog signals; and, by a somewhat loose convention, the messages conveyed via these carriers are called analog-form information, or simply analog information. Until the development of the digital computer, cognitive information was stored and processed only in analog form, basically through the technologies of printing, photography, and telephony.
Although humans are adept at processing information stored in their memories, analog information stored external to the mind is not processed easily. Modern information technology greatly facilitates the manipulation of externally stored information as a result of its representation as digital signals--i.e., as the presence or absence of energy (electricity, light, or magnetism). Information represented digitally in two-state, or binary, form is often referred to as digital information. Modern information systems are characterized by extensive metamorphoses of analog and digital information. With respect to information storage and communication, the transition from analog information to digital is so pervasive that the end of the 20th century will likely witness a historic transformation of the manner in which humans create, access, and use information.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The principal categories of information sources useful in modern information systems are text, video, and voice. One of the first ways in which prehistoric humans communicated was by sound; sounds represented concepts such as pleasure, anger, and fear, as well as objects of the surrounding environment, including food and tools. Sounds assumed their meaning by convention--namely, by the use to which they were consistently put. Combining parts of sound allowed representation of more complex concepts, gradually leading to the development of speech and eventually to spoken "natural" languages.
For information to be communicated broadly, it needs to be stored external to human memory; accumulation of human experience, knowledge, and learning would be severely limited without such storage, making necessary the development of writing systems.
Civilization can be traced to the time when humans began to associate abstract shapes with concepts and with the sounds of speech that represented them. Early recorded representations were those of visually perceived objects and events, as, for example, the animals and activities depicted in Paleolithic cave drawings. The evolution of writing systems proceeded through the early development of pictographic languages, in which a symbol would represent an entire concept. Such symbols would go through many metamorphoses of shape in which the resemblance between each symbol and the object it stood for gradually disappeared, but its semantic meaning would become more precise. As the conceptual world of humans became larger, the symbols, called ideographs, grew in number. Modern Chinese, a present-day result of this evolutionary direction of a pictographic writing system, has upward of 50,000 ideographs.
At some point in the evolution of written languages, the method of representation shifted from the pictographic to the phonetic: speech sounds began to be represented by an alphabet of graphic symbols. Combinations of a relatively small set of such symbols could stand for more complex concepts as words, phrases, and sentences. The invention of the written phonetic alphabet is thought to have taken place during the 2nd millennium BC. The pragmatic advantages of alphabetic writing systems over the pictographic became apparent twice in the present millennium: after the invention of the movable-type printing press in the 15th century and again with the development of information processing by electronic means since the mid-1940s.
From the time early humans learned to represent concepts symbolically, they used whatever materials were readily available in nature for recording. The Sumerian cuneiform, a wedge-shaped writing system, was impressed by a stylus into soft clay tablets, which were subsequently hardened by drying in the sun or the oven. The earliest Chinese writing, dating to the 2nd millennium BC, is preserved on animal bone and shell, while early writing in India was done on palm leaves and birch bark. Applications of technology yielded other materials for writing. The Chinese had recorded their pictographs on silk, using brushes made from animal hair, long before they invented paper. The Egyptians first wrote on cotton, but they began using papyrus sheets and rolls made from the fibrous lining of the papyrus plant during the 4th millennium BC. The reed brush and a palette of ink were the implements with which they wrote hieroglyphic script. Writing on parchment, a material which was superior to papyrus and was made from the prepared skins of animals, became commonplace about 200 BC, some 300 years after its first recorded use, and the quill pen replaced the reed brush. By the 4th century AD, parchment came to be the principal writing material in Europe.
Paper was invented in China at the beginning of the 2nd century AD, and for some 600 years its use was confined to East Asia. In AD 751 Arab and Chinese armies clashed at the Battle of Talas, near Samarkand; among the Chinese taken captive were some papermakers from whom the Arabs learned the techniques. From the 7th century on, paper became the dominant writing material of the Islamic world. Papermaking finally reached Spain and Sicily in the 12th century, and it took another three centuries before it was practiced in Germany.
With the invention of printing from movable type, typesetting became the standard method of creating copy. Typesetting was an entirely manual operation until the adoption of a typewriter-like keyboard in the 19th century. In fact, it was the typewriter that mechanized the process of recording original text. Although the typewriter was invented during the early 18th century in England, the first practical version, constructed by the American inventor Christopher Latham Sholes, did not appear until 1867. The mechanical typewriter finally found wide use after World War I. Today its electronic variant, the computer video terminal, is used pervasively to record original text.
Recording of original nontextual (image) information was a manual process until the development of photography during the early decades of the 19th century; drawing and carving were the principal early means of recording graphics. Other techniques were developed alongside printing--for example, etching in stone and metal. The invention of film and the photographic process added a new dimension to information acquisition: for the first time, complex visual images of the real world could be captured accurately. Photography provided a method of storing information in less space and more accurately than was previously possible with narrative information.
During the 20th century, versatile electromagnetic media have opened up new possibilities for capturing original analog information. Magnetic audio tape is used to capture speech and music, and magnetic videotape provides a low-cost medium for recording analog voice and video signals directly and simultaneously. Magnetic technology has other uses in the direct recording of analog information, including alphanumerics. Magnetic characters, bar codes, and special marks are printed on checks, labels, and forms for subsequent sensing by magnetic or optical readers and conversion to digital form. Banks, educational institutions, and the retail industry rely heavily on this technology. Nonetheless, paper and film continue to be the dominant media for direct storage of textual and visual information in analog form.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The versatility of modern information systems stems from their ability to represent information electronically as digital signals and to manipulate it automatically at exceedingly high speeds. Information is stored in binary devices, which are the basic components of digital technology. Because these devices exist only in one of two states, information is represented in them either as the absence or the presence of energy (electric pulse). The two states of binary devices are conveniently designated by the binary digits, or bits, zero (0) and one (1).
In this manner, alphabetic symbols of natural-language writing systems can be represented digitally as combinations of zeros (no pulse) and ones (pulse). Tables of equivalences of alphanumeric characters and strings of binary digits are called coding systems, the counterpart of writing systems. A combination of three binary digits can represent up to eight such characters; one comprising four digits, up to 16 characters; and so on. The choice of a particular coding system depends on the size of the character set to be represented. The widely used systems are the American Standard Code for Information Interchange (ASCII), a seven- or eight-bit code representing the English alphabet, numerals, and certain special characters of the standard computer keyboard; and the corresponding eight-bit Extended Binary Coded Decimal Interchange Code (EBCDIC), used for computers produced by IBM (International Business Machines Corp.) and most compatible systems. The digital representation of a character by eight bits is called a byte.
The seven-bit ASCII code is capable of representing up to 128 alphanumeric and special characters--sufficient to accommodate the writing systems of many phonetic scripts, including Latin and Cyrillic. Some alphabetic scripts require more than seven bits; for example, the Arabic alphabet, also used in the Urdu and Persian languages, has 28 consonantal characters (as well as a number of vowels and diacritical marks), but each of these may have four shapes, depending on its position in the word.
For digital representation of nonalphabetic writing systems, even the eight-bit code accommodating 256 characters is inadequate. Some writing systems that use Chinese characters, for example, have more than 50,000 ideographs (the minimal standard font for the Hanzi system in Chinese and the kanji system in Japanese has about 7,000 ideographs). Digital representation of such scripts can be accomplished in three ways. One approach is to develop a phonetic character set; the Chinese Pinyin, the Korean Hangul, and the Japanese hiragana phonetic schemes all have alphabetic sets similar in number to the Latin alphabet. As the use of phonetic alphabets in Oriental cultures is not yet widespread, they may be converted to ideographic by means of a dictionary lookup. A second technique is to decompose ideographs into a small number of elementary signs called strokes, the sum of which constitutes a shape-oriented, nonphonetic alphabet. The third approach is to use more than eight bits to encode the large numbers of ideographs; for instance, two bytes can represent uniquely more than 65,000 ideographs. Because the eight-bit ASCII code is inadequate for a number of writing systems, either because they are nonalphabetic or because their phonetic scripts possess large numbers of diacritical marks, the computer industry in 1991 began formulating a new international coding standard based on 16 bits.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Punched cards and perforated paper tape were once widely used to store data in binary form. Today they have been supplanted by media based on electromagnetic and electro-optic technologies except in a few special applications
Present-day storage media are of two types: random- and serial-, or sequential-, access. In random-access media (such as primary memory) the time required to access a given piece of data is independent of its location, while in serial-access media the access time depends on the data's location and the position of the read-write head. The typical serial-access medium is magnetic tape. The storage density of magnetic tape has increased considerably over the years, mainly by increases in the number of tracks packed across the width of the tape.
While magnetic tape remains a popular choice in applications requiring low-cost auxiliary storage and data exchange, new tape variants have begun entering the market of the 1990s. Video recording tape has been adapted for digital storage, and digital audio tape (DAT) surpasses all tape storage devices in offering the highest areal data densities. DAT technology uses a helical-scan recording method in which both the tape and the recording head move simultaneously, allowing extremely high recording densities. A four-millimetre DAT tape cassette has a capacity of up to eight billion bytes (eight gigabytes). The capacity of this tape is expected to increase by an order of magnitude well before the year 2000.
Another type of magnetic storage medium, the magnetic disk, provides rapid, random access to data. This device, developed in 1962, consists of either an aluminum or plastic platen coated with a metallic material. Information is recorded on a disk by turning the charge of the read-write head on and off, which produces magnetic "dots" representing binary digits in circular tracks. A block of data on a given track can be accessed without having to pass over a large portion of its contents sequentially, as in the case of tape. Data-retrieval time is thus reduced dramatically. Hard disk drives built into personal computers and workstations have storage capacities of up to several gigabytes. Large computers using disk cartridges can provide virtually unlimited mass storage.
During the 1970s the floppy disk--a small, flexible disk--was introduced for use in personal computers and other microcomputer systems. Compared with the storage capacity of the conventional hard disk, that of such a "soft" diskette is low--under three million characters. This medium is used primarily for loading and backing up personal computers.
An entirely different kind of recording and storage medium, the optical disc, became available during the early 1980s. The optical disc makes use of laser technology: digital data are recorded by burning a series of microscopic holes, or pits, with a laser beam into thin metallic film on the surface of a 4 3/4-inch (12-centimetre) plastic disc. In this way, information from magnetic tape is encoded on a master disc; subsequently, the master is replicated by a process called stamping. In the read mode, low-intensity laser light is reflected off the disc surface and is "read" by light-sensitive diodes. The radiant energy received by the diodes varies according to the presence of the pits, and this input is digitized by the diode circuits. The digital signals are then converted to analog information on a video screen or in printout form.
Since the introduction of this technology, three main types of optical storage media have become available: (1) rewritable, (2) write-once read-many (WORM), and (3) compact disc read-only memory (CD-ROM). Rewritable discs are functionally equivalent to magnetic disks, although the former are slower. WORM discs are used as an archival storage medium to enter data once and retrieve it many times. CD-ROMs are the preferred medium for electronic distribution of digital libraries and software. To raise storage capacity, optical discs are arranged into "jukeboxes" holding as many as 10 million pages of text or more than one terabyte (one trillion bytes) of image data. The high storage capacities and random access of the magneto-optical, rewritable discs are particularly suited for storing multimedia information, in which text, image, and sound are combined.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Digitally stored information is commonly referred to as data, and its analog counterpart is called source data. Vast quantities of nondocument analog data are collected, digitized, and compressed automatically by means of appropriate instruments in fields such as astronomy, environmental monitoring, scientific experimentation and modeling, and national security. The capture of information generated by humankind, in the form of packages of symbols called documents, is accomplished by manual and, increasingly, automatic techniques. Data are entered manually by striking the keys of a keyboard, touching a computer screen, or writing by hand on a digital tablet or its recent variant, the so-called pen computer. Manual data entry, a slow and error-prone process, is facilitated to a degree by special computer programs that include editing software, with which to insert formatting commands, verify spelling, and make text changes, and document-formatting software, with which to arrange and rearrange text and graphics flexibly on the output page.
It is estimated that 5 percent of all documents in the United States exist in digitized form and that two-thirds of the paper documents cannot be digitized by keyboard transcription because they contain drawings or still images and because such transcription would be highly uneconomic. Such documents are digitized economically by a process called document imaging (see Figure 2 Document imaging.).
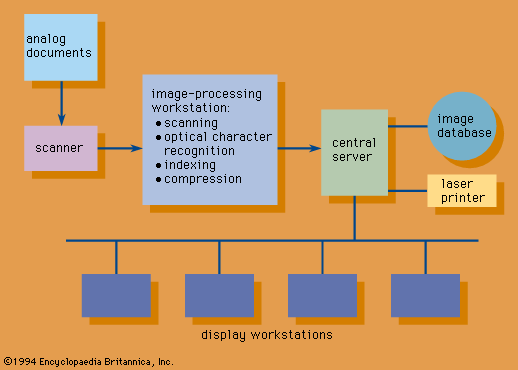
Document imaging utilizes digital scanners to generate a digital representation of a document page. An image scanner divides the page into minute picture areas called pixels and produces an array of binary digits, each representing the brightness of a pixel. The resulting stream of bits is enhanced and compressed (to as little as 10 percent of the original volume) by a device called an image controller and is stored on a magnetic or optical medium. A large storage capacity is required, because it takes about 45,000 bytes to store a typical compressed text page of 2,500 characters and as much as 1,000,000 bytes to store a page containing an image. Aside from document imaging applications, digital scanning is used for transmission of documents via facsimile, in satellite photography, and in other applications.
An image scanner digitizes an entire document page for storage and display as an image and does not recognize characters and words of text. The stored material therefore cannot be linguistically manipulated by text processing and other software techniques. When such manipulation is desired, a software program performs the optical character recognition (OCR) function by converting each optically scanned character into an electric signal and comparing it with the internally stored representation of an alphabet of characters, so as to select from it the one that matches the scanned character most closely or to reject it as an unidentifiable token. The more sophisticated of present-day OCR programs distinguish shapes, sizes, and pitch of symbols--including handwriting--and learn from experience. A universal optical character recognition machine is not available, however, for even a single alphabet.
Still photographs can be digitized by scanning or transferred from film to a compact digital disc holding more than 100 images. A recent development, the digital camera, makes it possible to bypass the film/paper step completely by capturing the image into the camera's random-access memory or a special diskette and then transferring it to a personal computer. Since both technologies produce a graphics file, in either case the image is editable by means of suitable software.
The digital recording of sound is important, because speech is the most frequently used natural carrier of communicable information. Direct capture of sound into personal computers is accomplished by means of a digital signal processor (DSP) chip, a special-purpose device built into the computer to perform array-processing operations. Conversion of analog audio signals to digital recordings is a commonplace process that has been used for years by the telecommunications and entertainment industries. Although the resulting digital sound track can be edited, automatic speech recognition--analogous to the recognition of characters and words in text by means of optical character recognition--is still under development. When perfected, voice recognition is certain to have a tremendous impact on the way humans communicate with recorded information, with computers, and among themselves.
By the beginning of the 1990s, the technology to record (or convert), store in digital form, and edit all visually and aurally perceived signals--text, graphics, still images, animation, motion video, and sound--had thus become available and affordable. These capabilities have opened a way for a new kind of multimedia document that employs print, video, and sound to generate more powerful and colourful messages, communicate them securely at electronic speeds, and allow them to be modified almost at will. The traditional business letter, newspaper, journal, and book will no longer be the same.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The development of recording media and techniques enabled society to begin building a store of human knowledge. The idea of collecting and organizing written records is thought to have originated in Sumer about 5,000 years ago; Egyptian writing was introduced soon after. Early collections of Sumerian and Egyptian writings, recorded in cuneiform on clay tablets and in hieroglyphic script on papyrus, contained information about legal and economic transactions. In these and other early document collections (e.g., those of China produced during the Shang dynasty in the 2nd millennium BC and Buddhist collections in India dating to the 5th century BC), it is difficult to separate the concepts of the archive and the library.
From the Middle East the concept of document collections penetrated the Greco-Roman world. Roman kings institutionalized the population and property census as early as the 6th century BC. The great Library of Alexandria, established in the 3rd century BC, is best known as a large collection of papyri containing inventories of property, taxes, and other payments by citizens to their rulers and to each other. It is, in short, the ancient equivalent of today's administrative information systems.
The scholarly splendour of the Islamic world from the 8th to 13th century AD can in large part be attributed to the maintenance of public and private book libraries. The Bayt al-Hikmah ("House of Wisdom"), founded in AD 830 in Baghdad, contained a public library with a large collection of materials on a wide range of subjects, and the 10th-century library of Caliph al-Hakam in Cordova, Spain, boasted more than 400,000 books.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The late but rapid development of European libraries from the 16th century on followed the invention of printing from movable type, which spurred the growth of the printing and publishing industries. Since the beginning of the 17th century, literature has become the principal medium for disseminating knowledge. The phrase primary literature is used to designate original information in various printed formats: newspapers, monographs, conference proceedings, learned and trade journals, reports, patents, bulletins, and newsletters. The scholarly journal, the classic medium of scientific communication, first appeared in 1665. Three hundred years later the number of periodical titles published in the world was estimated at more than 60,000, reflecting not only growth in the number of practitioners of science and expansion of its body of knowledge through specialization but also a maturing of the system of rewards that encourages scientists to publish.
The sheer quantity of printed information has for some time prevented any individual from fully absorbing even a minuscule fraction of it. Such devices as tables of contents, summaries, and indexes of various types, which aid in identifying and locating relevant information in primary literature, have been in use since the 16th century and led to the development of what is termed secondary literature during the 19th century. The purpose of secondary literature is to "filter" the primary information sources, usually by subject area, and provide the indicators to this literature in the form of reviews, abstracts, and indexes. Over the past 100 years there has evolved a system of disciplinary, national, and international abstracting and indexing services that acts as a gateway to several attributes of primary literature: authors, subjects, publishers, dates (and languages) of publication, and citations. The professional activity associated with these access-facilitating tools is called documentation.
The quantity of printed materials also makes it impossible, as well as undesirable, for any institution to acquire and house more than a small portion of it. The husbanding of recorded information has become a matter of public policy, as many countries have established national libraries and archives to direct the orderly acquisition of analog-form documents and records. Since these institutions alone are not able to keep up with the output of such documents and records, new forms of cooperative planning and sharing recorded materials are evolving--namely, public and private, national and regional library networks and consortia.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The emergence of digital technology in the mid-20th century has affected humankind's inventory of recorded information dramatically. During the early 1960s computers were used to digitize text for the first time; the purpose was to reduce the cost and time required to publish two American abstracting journals, the Index Medicus of the National Library of Medicine and the Scientific and Technical Aerospace Reports of the National Aeronautics and Space Administration (NASA). By the late 1960s such bodies of digitized alphanumeric information, known as bibliographic and numeric databases, constituted a new type of information resource. This resource is husbanded outside the traditional repositories of information (libraries and archives) by database "vendors." Advances in computer storage, telecommunications, software for computer sharing, and automated techniques of text indexing and searching fueled the development of an on-line database service industry. Meanwhile, electronic applications to bibliographic control in libraries and archives have led to the development of computerized catalogs and of union catalogs in library networks. They also have resulted in the introduction of comprehensive automation programs in these institutions.
The explosive growth of communications networks after 1990, particularly in the scholarly world, has accelerated the establishment of the "virtual library." At the leading edge of this development is public-domain information. Residing in thousands of databases distributed worldwide, a growing portion of this vast resource is now accessible almost instantaneously via the Internet, the web of computer networks linking the global communities of researchers and, increasingly, nonacademic organizations. Internet resources of electronic information include selected library catalogs, collected works of the literature, some abstracting journals, full-text electronic journals, encyclopaedias, scientific data from numerous disciplines, software archives, demographic registers, daily news summaries, environmental reports, and prices in commodity markets, as well as hundreds of thousands of electronic-mail and bulletin-board messages.
The vast inventory of recorded information can be useful only if it is systematically organized and if mechanisms exist for locating in it items relevant to human needs. The main approaches for achieving such organization are reviewed in the following section, as are the tools used to retrieve desired information.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
In any collection, physical objects are related by order. The ordering may be random or according to some characteristic called a key. Such characteristics may be intrinsic properties of the objects (e.g., size, weight, shape, or colour), or they may be assigned from some agreed-upon set, such as object class or date of purchase. The values of the key are arranged in a sorting sequence that is dependent on the type of key involved: alphanumeric key values are usually sorted in alphabetic sequence, while other types may be sorted on the basis of similarity in class, such as books on a particular subject or flora of the same genus.
In most cases, order is imposed on a set of information objects for two reasons: to create their inventory and to facilitate locating specific objects in the set. There also exist other, secondary objectives for selecting a particular ordering, as, for example, conservation of space or economy of effort in fetching objects. Unless the objects in a collection are replicated, any ordering scheme is one-dimensional and unable to meet all the functions of ordering with equal effectiveness. The main approach for overcoming some of the limitations of one-dimensional ordering of recorded information relies on extended description of its content and, for analog-form information, of some features of the physical items. This approach employs various tools of content analysis that subsequently facilitate accessing and searching recorded information.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The collections of libraries and archives, the primary repositories of analog-form information, constitute one-dimensional ordering of physical materials in print (documents), in image form (maps and photographs), or in audio-video format (recordings and videotapes). To break away from the confines of one-dimensional ordering, librarianship has developed an extensive set of attributes in terms of which it describes each item in the collection. The rules for assigning these attributes are called cataloging rules. Descriptive cataloging is the extraction of bibliographic elements (author names, title, publisher, date of publication, etc.) from each item; the assignment of subject categories or headings to such items is termed subject cataloging.
Conceptually, the library catalog is a table or matrix in which each row describes a discrete physical item and each column provides values of the assigned key. When such a catalog is represented digitally in a computer, any attribute can serve as the ordering key. By sorting the catalog on different keys, it is possible to produce a variety of indexes as well as subject bibliographies. More importantly, any of the attributes of a computerized catalog becomes a search key (access point) to the collection, surpassing the utility of the traditional card catalog.
The most useful access key to analog-form items is subject. The extensive lists of subject headings of library classification schemes provide, however, only a gross access tool to the content of the items. A technique called indexing provides a refinement over library subject headings. It consists of extracting from the item or assigning to it subject and other "descriptors"--words or phrases denoting significant concepts (topics, names) that occur in or characterize the content of the record. Indexing frequently accompanies abstracting, a technique for condensing the full text of a document into a short summary that contains its main ideas (but invariably incurs an information loss and often introduces a bias). Computer-printed, indexed abstracting journals provide a means of keeping users informed of primary information sources.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The description of an electronic document generally follows the principles of bibliographic cataloging if the document is part of a database that is expected to be accessed directly and individually. When the database is an element of a universe of globally distributed database servers that are searchable in parallel, the matter of document naming is considerably more challenging, because several complexities are introduced. The document description must include the name of the database server--i.e., its physical location. Because database servers may delete particular documents, the description must also contain a pointer to the document's logical address (the generating organization). In contrast to their usefulness in the descriptive cataloging of analog documents, physical attributes such as format and size are highly variable in the milieu of electronic documents and therefore are meaningless in a universal document-naming scheme. On the other hand, the data type of the document (text, sound, etc.) is critical to its transmission and use. Perhaps the most challenging design is the "living document"--a constantly changing pastiche consisting of sections electronically copied from different documents, interspersed with original narrative or graphics or voice comments contributed by persons in distant locations, whose different versions reside on different servers. Efforts are under way to standardize the naming of documents in the universe of electronic networks.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The subject analysis of electronic text is accomplished by means of machine indexing, using one of two approaches: the assignment of subject descriptors from an unlimited vocabulary (free indexing) or their assignment from a list of authorized descriptors (controlled indexing). A collection of authorized descriptors is called an authority list or, if it also displays various relationships among descriptors such as hierarchy or synonymy, a thesaurus. The result of the indexing process is a computer file known as an inverted index, which is an alphabetic listing of descriptors and the addresses of their occurrence in the document body.
Full-text indexing, the use of every character string (word of a natural language) in the text as an index term, is an extreme case of free-text indexing: each word in the document (except function words such as articles and prepositions) becomes an access point to it. Used earlier for the generation of concordances in literary analysis and other computer applications in the humanities, full-text indexing placed great demands on computer storage because the resulting index is at least as large as the body of the text. With decreasing cost of mass storage, automatic full-text indexing capability has been incorporated routinely into state-of-the-art information-management software.
Text indexing may be supplemented by other syntactic techniques, so as to increase its precision or robustness. One such method, the Standard Generalized Markup Language (SGML), takes advantage of standard text markers used by editors to pinpoint the location and other characteristics of document elements (paragraphs and tables, for example). In indexing spatial data such as maps and astronomical images, the textual index specifies the search areas, each of which is further described by a set of coordinates defining a rectangle or irregular polygon. These digital spatial document attributes are then used to retrieve and display a specific point or a selected region of the document. There are other specialized techniques that may be employed to augment the indexing of specific document types, such as encyclopaedias, electronic mail, catalogs, bulletin boards, tables, and maps.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
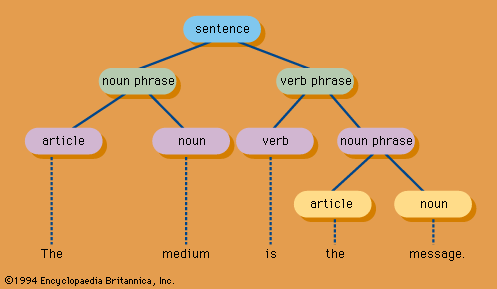
The analysis of digitally recorded natural-language information from the semantic viewpoint is a matter of considerable complexity, and it lies at the foundation of such incipient applications as automatic question answering from a database or retrieval by means of unrestricted natural-language queries. The general approach has been that of computational linguistics: to derive representations of the syntactic and semantic relations among the linguistic elements of sentences and larger parts of the document. Syntactic relations are described by parsing (decomposing) the grammar of sentences (Figure 3 A parsing graph.).
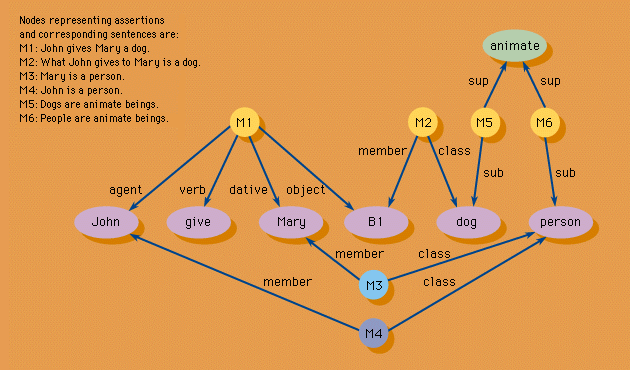
For semantic representation, three related formalisms dominate. In a so-called semantic network, conceptual entities such as objects, actions, or events are represented as a graph of linked nodes (Figure 4 Figure 4: A semantic network representation.). "Frames" represent, in a similar graph network, physical or abstract attributes of objects and in a sense define the objects. In "scripts," events and actions rather than objects are defined in terms of their attributes.
Indexing and linguistic analyses of text generate a relatively gross measure of the semantic relationship, or subject similarity, of documents in a given collection. Subject similarity is, however, a pragmatic phenomenon that varies with the observer and the circumstances of an observation (purpose, time, and so forth). A technique experimented with briefly in the mid-1960s, which assigned to each document one or more "roles" (functions) and one or more "links" (pointers to other documents having the same or a similar role), showed potential for a pragmatic measure of similarity; its use, however, was too unwieldy for the computing environment of the day. Some 20 years later, a similar technique became popular under the name "hypertext." In this technique, documents that a person or a group of persons consider related (by concept, sequence, hierarchy, experience, motive, or other characteristics) are connected via "hyperlinks," mimicking the way humans associate ideas. Objects so linked need not be only text; speech and music, graphics and images, and animation and video can all be interlinked into a "hypermedia" database. The objects are stored with their hyperlinks, and a user can easily navigate the network of associations by clicking with a mouse on a series of entries on a computer screen. Another technique that elicits semantic relationships from a body of text is SGML.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The content analysis of images is accomplished by two primary methods: image processing and pattern recognition. Image processing is a set of computational techniques for analyzing, enhancing, compressing, and reconstructing images. Pattern recognition is an information-reduction process: the assignment of visual or logical patterns to classes based on the features of these patterns and their relationships. The stages in pattern recognition involve measurement of the object to identify distinguishing attributes, extraction of features for the defining attributes, and assignment of the object to a class based on these features. Both image processing and pattern recognition have extensive applications in various areas, including astronomy, medicine, industrial robotics, and remote sensing by satellites.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The immediate objective of content analysis of digital speech is the conversion of discrete sound elements into their alphanumeric equivalents. Once so represented, speech can be subjected to the same techniques of content analysis as natural-language text--i.e., indexing and linguistic analysis. Converting speech elements into their alphanumeric counterparts is an intriguing problem because the "shape" of speech sounds embodies a wide range of many acoustic characteristics and because the linguistic elements of speech are not clearly distinguishable from one another. The technique used in speech processing is to classify the spectral representations of sound and to match the resulting digital spectrographs against prestored "templates" so as to identify the alphanumeric equivalent of the sound. (The obverse of this technique, the digital-to-analog conversion of such templates into sound, is a relatively straightforward approach to generating synthetic speech.)
Speech processing is complex as well as expensive in terms of storage capacity and computational requirements. State-of-the-art speech recognition systems can identify limited vocabularies and parts of distinctly spoken speech and can be programmed to recognize tonal idiosyncracies of individual speakers. When more robust and reliable techniques become available and the process is made computationally tractable (as is expected with parallel computers), humans will be able to interact with computers via spoken commands and queries on a routine basis. In many situations this may make the keyboard obsolete as a data-entry device.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Digital information is stored in complex patterns that make it feasible to address and operate on even the smallest element of symbolic expression, as well as on larger strings such as words or sentences and on images and sound.
From the viewpoint of digital information storage, it is useful to distinguish between "structured" data, such as inventories of objects that can be represented by short symbol strings and numbers, and "unstructured" data, such as the natural-language text of documents or pictorial images. The principal objective of all storage structures is to facilitate the processing of data elements based on their relationships; the structures thus vary with the type of relationship they represent. The choice of a particular storage structure is governed by the relevance of the relationships it allows to be represented to the information-processing requirements of the task or system at hand.
In information systems whose store consists of unstructured databases of natural-language records, the objective is to retrieve records (or portions thereof) based on the presence in the records of words or short phrases that constitute the query. Since there exists an index as a separate file that provides information about the locations of words and phrases in the database records, the relationships that are of interest (e.g., word adjacency) can be calculated from the index. Consequently, the database text itself can be stored as a simple ordered sequential file of records. The majority of the computations use the index, and they access the text file only to pull out the records or those portions that satisfy the result of the computations. The sequential file structure remains popular, with document-retrieval software intended for use with personal computers and CD-ROM databases.
When relationships among data elements need to be represented as part of the records so as to make more efficient the desired operations on these records, two types of "chained" structures are commonly used: hierarchical and network. In the hierarchical file structure, records are arranged in a scheme resembling a family tree, with records related to one another from top to bottom. In the network file structure, records are arranged in groupings known as sets; these can be connected in any number of ways, giving rise to considerable flexibility. In both hierarchical and network structures, the relationships are shown by means of "pointers" (i.e., identifiers such as addresses or keys) that become part of the records.
Another type of database storage structure, the relational structure, has become increasingly popular since the late 1970s. Its major advantage over the hierarchical and network structures is the ability to handle unanticipated data relationships without pointers. Relational storage structures are two-dimensional tables consisting of rows and columns, much like the conceptual library catalog mentioned above. The elegance of the relational model lies in its conceptual simplicity, the availability of theoretical underpinnings (relational algebra), and the ability of its associated software to handle data relationships without the use of pointers. The relational model was initially used for databases containing highly structured information. In the 1990s it has largely replaced the hierarchical and network models, and it has also become the model of choice for large-scale information-management applications, both textual and multimedia.
The feasibility of storing large volumes of full text on an economic medium (the digital optical disc) has renewed interest in the study of storage structures that permit more powerful retrieval and processing techniques to operate on cognitive entities other than words, to facilitate more extensive semantic content and context analysis, and to organize text conceptually into logical units rather than those dictated by printing conventions.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The uses of databases are manifold. They provide a means of retrieving records or parts of records and performing various calculations before displaying the results. The interface by which such manipulations are specified is called the query language. Whereas early query languages were originally so complex that interacting with electronic databases could be done only by specially trained individuals, recent interfaces are more user-friendly, allowing casual users to access database information.
The main types of popular query modes are the "menu," the"fill-in-the-blank" technique, and the structured query. Particularly suited for novices, the menu requires a person to choose from several alternatives displayed on the video terminal screen. The fill-in-the-blank technique is one in which the user is prompted to enter key words as search statements. The structured query approach is effective with relational databases. It has a formal, powerful syntax that is in fact a programming language, and it is able to accommodate logical operators. One implementation of this approach, the Structured Query Language (SQL), has the form
select [field Fa, Fb, . . . , Fn] from [database Da, Db, . . . , Dn] where [field Fa = abc] and [field Fb = def].
Structured query languages support database searching and other operations by using commands such as "find," "delete," "print," "sum," and so forth. The sentencelike structure of an SQL query resembles natural language except that its syntax is limited and fixed. Instead of using an SQL statement, it is possible to represent queries in tabular form. The technique, referred to as query-by-example (or QBE), displays an empty tabular form and expects the searcher to enter the search specifications into appropriate columns. The program then constructs an SQL-type query from the table and executes it.
The most flexible query language is of course natural language. The use of natural-language sentences in a constrained form to search databases is allowed by some commercial database management software. These programs parse the syntax of the query; recognize its action words and their synonyms; identify the names of files, records, and fields; and perform the logical operations required. Experimental systems that accept such natural-language queries in spoken voice have been developed; however, the ability to employ unrestricted natural language to query unstructured information will require further advances in machine understanding of natural language, particularly in techniques of representing the semantic and pragmatic context of ideas. The prospect of an intelligent conversation between humans and a large store of digitally encoded knowledge is not imminent.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
State-of-the-art approaches to retrieving information employ two generic techniques: (1) matching words in the query against the database index (key-word searching) and (2) traversing the database with the aid of hypertext or hypermedia links.
Key-word searches can be made either more general or more narrow in scope by means of logical operators (e.g., disjunction and conjunction). Because of the semantic ambiguities involved in free-text indexing, however, the precision of the key-word retrieval technique--that is, the percentage of relevant documents correctly retrieved from a collection--is far from ideal, and various modifications have been introduced to improve it. In one such enhancement, the search output is sorted by degree of relevance, based on a statistical match between the key words in the query and in the document; in another, the program automatically generates a new query using one or more documents considered relevant by the user. Key-word searching has been the dominant approach to text retrieval since the early 1960s; hypertext has so far been largely confined to personal or corporate information-retrieval applications.
The exponential growth of the use of computer networks in the 1990s presages significant changes in systems and techniques of information retrieval. In a wide-area information service, a number of which began operating at the beginning of the 1990s on the Internet computer network, a user's personal computer or terminal (called a client) can search simultaneously a number of databases maintained on heterogeneous computers (called servers). The latter are located at different geographic sites, and their databases contain different data types and often use incompatible data formats. The simultaneous, distributed search is possible because clients and servers agree on a standard document addressing scheme and adopt a common communications protocol that accommodates all the data types and formats used by the servers. Communication with other wide-area services using different protocols is accomplished by routing through so-called gateways capable of protocol translation. The architecture of a typical networked information system is illustrated in Figure 5

The architecture of a networked information system.. Several representative clients are shown: a "dumb" terminal (i.e., one with no internal processor), a personal computer (PC), and Macintosh (trademark; Mac), and NeXT (trademark) machines. They have access to data on the servers sharing a common protocol as well as to data provided by services that require protocol conversion via the gateways. Network news is such a wide-area service, containing hundreds of news groups on a variety of subjects, by which users can read and post messages.
Evolving information-retrieval techniques, exemplified by an experimental interface to the NASA space shuttle reference manual, combine natural language, hyperlinks, and key-word searching. Other techniques, seeking higher levels of retrieval precision and effectiveness, are studied by researchers involved with artificial intelligence and neural networks. The next major milestone may be a computer program that traverses the seamless information universe of wide-area electronic networks and continuously filters its contents through profiles of organizational and personal interest: the information robot of the 21st century.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
For humans to perceive and understand information, it must be presented as print and image on paper; as print and image on film or on a video terminal; as sound via radio or telephony; as print, sound, and video in motion pictures, on television broadcasts, or at lectures and conferences; or in face-to-face encounters. Except for live encounters and audio information, such displays emanate increasingly from digitally stored data, with the output media being video, print, and sound.
Possibly the most widely used video display device, at least in the industrialized world, is the television set. Designed primarily for video and sound, its image resolution is inadequate for alphanumeric data except in relatively small amounts. Use of the television set in text-oriented information systems has been limited to menu-oriented applications such as videotex, in which information is selected from hierarchically arranged menus (with the aid of a numeric keyboard attachment) and displayed in fixed frames. The television, computer, and communications technologies are, however, converging in a high-resolution digital television set capable of receiving alphanumeric, video, and audio signals.
The computer video terminal is today's ubiquitous interface that transforms computer-stored data into analog form for human viewing. The two basic apparatuses used are the cathode-ray tube (CRT) and the more recent flat-panel display. In CRT displays an electron gun emits beams of electrons on a phosphorus-coated surface; the beams are deflected, forming visible patterns representative of data. Flat-panel displays use one of four different media for visual representation of data: liquid crystal, light-emitting diodes, plasma panels, and electroluminescence. Advanced video display systems enable the user to scroll, page, zoom (change the scale of the details of the display image for enhancement), divide the screen into multiple colours and windows (viewing areas), and in some cases even activate commands by touching the screen instead of using the keyboard. The information capacity of the terminal screen depends on its resolution, which ranges from low (character-addressable) to high (bit-addressable). High resolution is indispensable for the display of graphic and video data in state-of-the-art workstations, such as those used in engineering or information systems design.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Modern society continues to be dominated by printed information. The convenience and portability of print on paper make it difficult to imagine the paperless world that some have predicted. The generation of paper print has changed considerably, however. Although manual typesetting is still practiced for artwork, in special situations, and in some developing countries, electronic means of composing pages for subsequent reproduction by photoduplication and other methods has become commonplace.
Since the 1960s, volume publishing has become an automated process using large computers and high-speed printers to transfer digitally stored data on paper. The appearance of microcomputer-based publishing systems has proved to be another significant advance. Economical enough to allow even small organizations to become in-house publishers, these so-called desktop publishing systems are able to format text and graphics interactively on a high-resolution video screen with the aid of page-description command languages. Once a page has been formatted, the entire image is transferred to an electronic printing or photocomposition device.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Computer printers are commonly divided into two general classes according to the way they produce images on paper: impact and nonimpact. In the first type, images are formed by the print mechanism making contact with the paper through an ink-coated ribbon. The mechanism consists either of print hammers shaped like characters or of a print head containing a row of pins that produce a pattern of dots in the form of characters or other images.
Most nonimpact printers form images from a matrix of dots, but they employ different techniques for transferring images to paper. The most popular type, the laser printer, uses a beam of laser light and a system of optical components to etch images on a photoconductor drum from which they are carried via electrostatic photocopying to paper. Light-emitting diode (LED) printers resemble laser printers in operation but direct light from energized diodes rather than a laser onto a photoconductive surface. Ion-deposition printers make use of technology similar to that of photocopiers for producing electrostatic images. Another type of nonimpact printer, the ink-jet printer, sprays electrically charged drops of ink onto the print surface.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Alphanumeric and image information can be transferred from digital computer storage directly to film. Reel microfilm and microfiche (a flat sheet of film containing multiple microimages reduced from the original) were popular methods of document storage and reproduction for several decades. During the 1990s they have been largely replaced by optical disc technology (see above Recording media).
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
In synthetic speech generation, digitally prestored sound elements are converted to analog sound signals and combined to form words and sentences. Digital-to-analog converters are available as inexpensive boards for microcomputers or as software for larger machines. Human speech is the most effective natural form of communication, and so applications of this technology are becoming increasingly popular in situations where there are numerous requests for specific information (e.g., time, travel, and entertainment), where there is a need for repetitive instruction, in electronic voice mail (the counterpart of electronic text mail), and in toys.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The process of recording information by handwriting was obviously laborious and required the dedication of the likes of Egyptian scribes or monks in monasteries around the world. It was only after mechanical means of reproducing writing were invented that information records could be duplicated more efficiently and economically.
The first practical method of reproducing writing mechanically was block printing; it was developed in China during the T'ang dynasty (618-907). Ideographic text and illustrations were engraved in wooden blocks, inked, and copied on paper. Used to produce books as well as cards, charms, and calendars, block printing spread to Korea and Japan but apparently not to the Islamic or European Christian civilizations. European woodcuts and metal engravings date only to the 14th century.
Printing from movable type was also invented in China (in the mid-11th century AD). There and in the bookmaking industry of Korea, where the method was applied more extensively during the 15th century, the ideographic type was made initially of baked clay and wood and later of metal. The large number of typefaces required for pictographic text composition continued to handicap printing in the Orient until the present time.
The invention of character-oriented printing from movable type (1440-50) is attributed to the German printer Johannes Gutenberg. Within 30 years of his invention, the movable-type printing press was in use throughout Europe. Character-type pieces were metallic and apparently cast from metallic molds; paper and vellum (calfskin parchment) were used to carry the impressions. Gutenberg's technique of assembling individual letters by hand was employed until 1886, when the German-born American printer Ottmar Mergenthaler developed the Linotype, a keyboard-driven device that cast lines of type automatically. Typesetting speed was further enhanced by the Monotype technique, in which a perforated paper ribbon, punched from a keyboard, was used to operate a type-casting machine. Mechanical methods of typesetting prevailed until the 1960s. Since that time they have been largely supplanted by the electronic and optical printing techniques described in the previous section.
Unlike the use of movable type for printing text, early graphics were reproduced from wood relief engravings in which the nonprinting portions of the image were cut away. Musical scores, on the other hand, were reproduced from etched stone plates. At the end of the 18th century the German printer Aloys Senefelder developed lithography, a planographic technique of transferring images from a specially prepared surface of stone. In offset lithography the image is transferred from zinc or aluminum plates instead of stone, and in photoengraving such plates are superimposed with film and then etched.
The first successful photographic process, the daguerreotype, was developed during the 1830s. The invention of photography, aside from providing a new medium for capturing still images and later video in analog form, was significant for two other reasons. First, recorded information (textual and graphic) could be easily reproduced from film and, second, the image could be enlarged or reduced. Document reproduction from film to film has been relatively unimportant, because both printing and photocopying (see above) are cheaper. The ability to reduce images, however, has led to the development of the microform, the most economical method of disseminating analog-form information.
Another technique of considerable commercial importance for the duplication of paper-based information is photocopying, or dry photography. Printing is most economical when large numbers of copies are required, but photocopying provides a fast and efficient means of duplicating records in small quantities for personal or local use. Of the several technologies that are in use, the most popular process, xerography, is based on electrostatics.
While the volume of information issued in the form of printed matter continues unabated, the electronic publishing industry has begun to disseminate information in digital form. The digital optical disc (see above Recording media) is developing as an increasingly popular means of issuing large bodies of archival information--for example, legislation, court and hospital records, encyclopaedias and other reference works, referral databases, and libraries of computer software. Full-text databases, each containing digital page images of the complete text of some 400 periodicals stored on CD-ROM, entered the market in 1990. The optical disc provides the mass production technology for publication in machine-readable form. It offers the prospect of having large libraries of information available in virtually every school and at many professional workstations.
The coupling of computers and digital telecommunications is also changing the modes of information dissemination. High-speed digital satellite communications facilitate electronic printing at remote sites; for example, the world's major newspapers and magazines transmit electronic page copies to different geographic locations for local printing and distribution. Updates of catalogs, computer software, and archival databases are distributed via electronic mail, a method of rapidly forwarding and storing bodies of digital information between remote computers.
Indeed, a large-scale transformation is taking place in modes of formal as well as informal communication. For more than three centuries, formal communication in the scientific community has relied on the scholarly and professional periodical, widely distributed to tens of thousands of libraries and to tens of millions of individual subscribers. In 1992 a major international publisher announced that its journals would gradually be available for computer storage in digital form; and in that same year the State University of New York at Buffalo began building a completely electronic, paperless library. The scholarly article, rather than the journal, is likely to become the basic unit of formal communication in scientific disciplines; digital copies of such an article will be transmitted electronically to subscribers or, more likely, on demand to individuals and organizations who learn of its existence through referral databases and new types of alerting information services. The Internet already offers instantaneous public access to vast resources of noncommercial information stored in computers around the world.
Similarly, the traditional modes of informal communications--various types of face-to-face encounters such as meetings, conferences, seminars, workshops, and classroom lectures--are being supplemented and in some cases replaced by electronic mail, electronic bulletin boards (a technique of broadcasting newsworthy textual and multimedia messages between computer users), and electronic teleconferencing and distributed problem-solving (a method of linking remote persons in real time by voice-and-image communication and special software called "groupware"). These technologies are forging virtual societal networks--communities of geographically dispersed individuals who have common professional or social interests.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The primary vehicles for the purposeful, orchestrated processing of information are information systems--constructs that collect, organize, store, process, and display information in all its forms (raw data, interpreted data, knowledge, and expertise) and formats (text, video, and voice). In principle, any record-keeping system--e.g., an address book or a train schedule--may be regarded as an information system. What sets modern information systems apart is their electronic dimension, which permits extremely fast, automated manipulation of digitally stored data and their transformation from and to analog representation.
Electronic information systems are a phenomenon of the second half of the 20th century. Their evolution is closely tied with advances in two basic technologies: integrated circuits and digital communications.
Integrated circuits are silicon chips containing transistors that store and process information. Advances in the design of these chips, which were first developed in 1958, are responsible for an exponential increase in the cost performance of computer components. For more than two decades the capacity of the basic integrated circuit, the dynamic random-access memory (DRAM) chip, has doubled consistently in intervals of less than two years: from 1,000 transistors (1 kilobit) per chip in 1970 to 1,000,000 (1 megabit) in 1987, 16 megabits in 1993, and 1,000,000,000 (1 gigabit) predicted for the year 2000. A gigabit chip has the capacity of 125,000,000 bytes, approximately equivalent to 14,500 pages, or more than 12 volumes, of Encyclop?dia Britannica.
The speed of microprocessor chips, measured in millions of instructions per second (MIPS), is also increasing near-exponentially: from 10 MIPS in 1985 to 100 MIPS in 1993, with 1,000 MIPS predicted for 1995. By the year 2000 a single chip may process 64 billion instructions per second. If in a particular computing environment in 1993 a chip supported 10 simultaneous users, in the year 2000 such a chip could theoretically support several thousand users.
Full exploitation of these developments for the realm of information systems requires comparable advances in software disciplines. Their major contribution has been to open the use of computer technology to persons other than computer professionals. Interactive applications in the office and home have been made possible by the development of easy-to-use software products for the creation, maintenance, manipulation, and querying of files and records. The database has become a central organizing framework for many information systems, taking advantage of the concept of data independence, which allows data sharing among diverse applications. Database management system (DBMS) software today incorporates high-level programming facilities that do not require one to specify in detail how the data should be processed. The programming discipline as a whole, however, progresses in an evolutionary manner. Whereas semiconductor field advances are measured by orders of magnitude, the writing and understanding of large suites of software that characterize complex information systems progress more slowly. The complexity of the data processes that comprise very large information systems has so far eluded major breakthroughs, and the cost-effectiveness of the software development sector improves only gradually.
The utility of computers is vastly augmented by their ability to communicate with one another, so as to share data and its processing. Local-area networks (LANs) permit the sharing of data, programs, printers, and electronic mail within offices and buildings. In wide-area networks, such as the Internet, which connect thousands of computers around the globe, computer-to-computer communication uses a variety of media as transmission lines--electric-wire audio circuits, coaxial cables, radio and microwaves (as in satellite communication), and, most recently, optical fibres. The latter are replacing coaxial cable in the Integrated Services Digital Network (ISDN), which is capable of carrying digital information in the form of voice, text, and video simultaneously. To communicate with another machine, a computer requires data circuit-terminating equipment, or DCE, which connects it to the transmission line. When an analog line such as a dial-up telephone line is used, the DCE is called a modem (for modulator/demodulator); it also provides the translation of the digital signal to analog and vice versa. By using data compression, the relatively inexpensive high-speed modems currently in use can transmit data at speeds of more than 100 kilobits per second. When digital lines are used, the DCE allows substantially higher speeds; for instance, the U.S. scholarly network NSFNET, set up by the National Science Foundation, transmits information at 45 million bits per second. The National Research and Education Network, proposed by the U.S. government in 1991, is designed to send data at speeds in the gigabit-per-second range, comfortably moving gigantic volumes of text, video, and sound across a web of digital highways.
Computer networks are complex entities. Each network operates according to a set of procedures called the network protocol. The proliferation of incompatible protocols during the early 1990s has been brought under relative control by the Open Systems Interconnection (OSI) reference Model formulated by the International Organization for Standardization. To the extent that individual protocols conform to the OSI recommendations, computer networks can now be interconnected efficiently through gateways.
Computer networking facilitates the current trend toward distributed information systems. At the corporate level, the central database may be distributed over a number of computer systems in different locations, yet its querying and updating are carried out simultaneously against the composite database. An individual searching for public-access information can traverse disparate computer networks to peruse hundreds of autonomous databases and within seconds or minutes download a copy of the desired document into a personal workstation.
The future of information systems may be gleaned from several areas of current research. As all information carriers (text, video, and sound) can be converted to digital form and manipulated by increasingly sophisticated techniques, the ranges of media, functions, and capabilities of information systems are constantly expanding. Evolving techniques of natural-language processing and understanding, knowledge representation, and neural process modeling have begun to join the more traditional repertoire of methods of content analysis and manipulation. The use of these techniques opens the possibility of eliciting new knowledge from existing data, such as the discovery of a previously unknown medical syndrome or of a causal relationship in a disease. Computer visualization, a new field that has grown expansively since the early 1990s, deals with the conversion of masses of data emanating from instruments, databases, or computer simulations into visual displays--the most efficient method of human information reception, analysis, and exchange. Related to computer visualization is the research area of virtual reality or virtual worlds, which denotes the generation of synthetic environments through the use of three-dimensional displays and interaction devices. A number of research directions in this area are particularly relevant to future information systems: knowledge-based world modeling; the development of physical analogues for abstract quantitative and organizational data; and search and retrieval in large virtual worlds. The cumulative effect of these new research areas is a gradual transformation of the role of information systems from that of data processing to that of cognition aiding.
Present-day computers are remarkably versatile machines capable of assisting humans in nearly every problem-solving task that involves symbol manipulations. Television, on the other hand, has penetrated societies throughout the world as a noninteractive display device for combined video and audio signals. The impending convergence of three digital technologies--namely, the computer, very-high-definition television (V-HDTV), and ISDN data communications--is all but inevitable. In such a system, a large-screen multimedia display monitor, containing a 64-megabit primary memory and a billion-byte hard disk for data storage and playback, would serve as a computer and, over ISDN fibre links, an interactive television receiver.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The building of information systems falls within the domain of engineering. As is true with other engineering disciplines, the nature and tools of information systems engineering are evolving owing to both technological developments and better perceptions of societal needs for information services. Early information systems were designed to be operated by information professionals, and they frequently did not attain their stated social purpose. Modern information systems are increasingly used by persons who have little or no previous hands-on experience with information technology but who possess a much better perception about what this technology should accomplish in their professional and personal environments. A correct understanding of the requirements, preferences, and "information styles" of these end users is crucial to the design and success of today's information systems.
The methodology involved in building an information system consists of a set of iterative activities that are cumulatively referred to as the system's life cycle (Figure 6
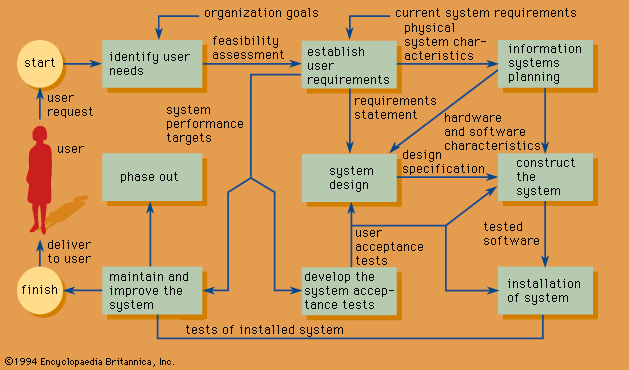
The life cycle of an information system.). The principal objective of the systems analysis phase is the specification of what the system is required to do. In the systems design phase such specifications are converted to a hierarchy of increasingly detailed charts that define the data required and decompose the processes to be carried out on data to a level at which they can be expressed as instructions of a computer program. The systems development phase consists of writing and testing computer software and of developing data input and output forms and conventions. Systems implementation is the installation of a physical system and the activities it entails, such as the training of operators and users. Systems maintenance refers to the further evolution of the functions and structure of a system that results from changing requirements and technologies, experience with the system's use, and fine-tuning of its performance.
Many information systems are implemented with generic, "off-the-shelf" software rather than with custom-built programs; versatile database management software and its nonprocedural programming languages fit the needs of small and large systems alike. The development of large systems that cannot use off-the-shelf software is an expensive, time-consuming, and complex undertaking. Prototyping, an interactive session in which users confirm a system's proposed functions and features early in the design stage, is a practice intended to raise the probability of success of such an undertaking. Some of the tools of computer-aided software engineering available to the systems analyst and designer verify the logic of systems design, automatically generate a program code from low-level specifications, and automatically produce software and system specifications. The eventual goal of information systems engineering is to develop software "factories" that use natural language and artificial intelligence techniques as part of an integrated set of tools to support the analysis and design of large information systems.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
A taxonomy of information systems is not easily developed, because of their diversity and continuing evolution in structure and function. Earlier distinctions--manual versus automated, interactive versus off-line, real-time versus batch-processing--are no longer appropriate. A more frequently made distinction is in terms of application: use in business offices, factories, hospitals, and so on. In the functional approach taken in this article, information systems may be divided into two categories: organizational systems and public information utilities. Information systems in formal organizations may be further distinguished according to their main purpose: support of managerial and administrative functions or support of operations and services. The former serve internal functions of the organizations, while the latter support the purposes for which these organizations exist.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The most important functions that top executives perform include setting policies, planning, and preparing budgets. At the strategic level, these decision-making functions are supported by executive information systems. The objective of these systems is to gather, analyze, and integrate internal (corporate) and external (public) data into dynamic profiles of key corporate indicators. Depending on the nature of the organization's business, such indicators may relate to the status of high-priority programs, health of the economy, inventory and cash levels, performance of financial markets, relevant efforts of competitors, utilization of manpower, legislative events, and so forth. The indicators are displayed as text, tables, graphics, or time series, and optional access is provided to more detailed data. The data emanate not only from within the organization's production and administrative departments but also from external information sources, such as public databases (Figure 7
Structure of a typical executive information system.). Present-day efforts, drawing on research in neural computers and networks, are to enhance executive information systems with adaptive and self-organizing abilities by means of learning from the executives' changing information needs and uses.
In military organizations, the approximate equivalent of executive information systems is command-and-control systems. Their purpose is to maintain control over some domain and, if needed, initiate corrective action. Their key characteristic is the real-time nature of the monitoring and decision-making functions. A command-and-control system typically assumes that the environment exercises pressure on the domain of interest (say, a naval force); the system then monitors the environment (collects intelligence data), analyzes the data, compares it with the desired state of the domain, and suggests actions to be taken. Systems of this kind are used at both strategic and tactical levels.
Both executive and military command-and-control systems make use of computational aids for data classification, modeling, and simulation. These capabilities are characteristic of a decision-support system (DSS), a composite of computer techniques for supporting executive decision making in relatively unstructured problem situations. Decision-support software falls into one of two categories: decision-aid programs, in which the decision maker assigns weighted values to every factor in the decision, and decision-modeling programs, in which the user explores different strategies to arrive at the desired outcome.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Administrative functions in formal organizations have as their objective the husbanding and optimization of corporate resources--namely, employees and their activities, inventories of materials and equipment, facilities, and finances. Administrative information systems support this objective. Commonly called management information systems (MIS), they focus primarily on resource administration and provide top management with reports of aggregate data. Executive information systems may be viewed as an evolution of administrative information systems in the direction of strategic tracking, modeling, and decision making.
Typically, administrative information systems consist of a number of modules, each supporting a particular function. The modules share a common database whose contents may, however, be distributed over a number of machines and locations. Financial information systems have evolved from the initial applications of punched cards before World War II to integrated accounting and finance systems that cover general accounting, accounts receivable and payable, payroll, purchasing, inventory control, and financial statements such as balance sheets. Functionally close to payroll systems are personnel information systems, which support the administration of the organization's human resources. Job and salary histories, inventory of skills, performance reviews, and other types of personnel data are combined in the database to assist personnel administration, explore potential effects of reorganization or new salary scales (or changes in benefits), and match job requirements with skills. Project management information systems concentrate on resource allocation and task completion of organized activities; they usually incorporate such scheduling methods as the critical path method (CPM) or program evaluation and review technique (PERT).
Since the advent of microcomputers, information processing in organizations has become heavily supported by office automation tools. These involve six basic applications: text processing, database, spreadsheet, graphics, communications, and networking. Administrative systems in smaller organizations are usually built as extensions of office automation tools; in large organizations these tools form an interface to custom software. The current trend in office automation is toward integrating the first five applications into a software utility, either delivered to each microprocessor workstation from a "server" on the corporate computer network or integrated into other applications software.
Administrative information systems abound in organizations in both the private and public sectors throughout the industrialized world. In the retail industry, point-of-sale terminals are linked into distributed administrative information systems that contain financial and inventory modules at the department, store, geographic area, and corporate chain levels, with modeling facilities that help to determine marketing strategies and optimize profits. Administrative information systems are indispensable to government; the agencies of virtually all U.S. municipalities with more than 10,000 inhabitants use such systems. The systems are generally centred around a generic database management system and are increasingly supported by software modules and programs that permit data modeling--i.e., they acquire management orientation.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Such information systems provide support for the operations or services that organizations perform for society. The systems are vertically oriented to specific sectors and industries (e.g., manufacturing, financial services, publishing, education, health, and entertainment). Rather than addressing management and administrative functions, they support activities and processes that are the reason for an organization's existence--in most cases, some kind of manufacturing activity or the rendering of services. Systems of this kind vary greatly, but they tend to fall into three main types: manufacturing, transaction, and expert systems.
Computer-integrated manufacturing
The conceptual goal of modern factories is computer-integrated manufacturing (CIM). The phrase denotes data-driven automation that affects all components of the manufacturing enterprise: design and development engineering, manufacturing, marketing and sales, and field support and service. Computer-aided design (CAD) systems were first applied in the electronics industry. Today they feature three-dimensional modeling techniques for drafting and manipulating solid objects on the screen and for deriving specifications for programs to drive numerical-control machines. Once a product is designed, its production process can be outlined using computer-aided process planning (CAPP) systems that help to select sequences of operations and machining conditions. Models of the manufacturing system can be simulated by computers before they are built. The basic manufacturing functions--machining, forming, joining, assembly, and inspection--are supported by computer-aided manufacturing (CAM) systems and automated materials-handling systems. Inventory control systems seek to maintain an optimal stock of parts and materials by tracking inventory movement, forecasting requirements, and initiating procurement orders.
The technological sophistication of manufacturing information systems is impressive, and it increasingly includes applications of robotics, computer vision, and expert systems (see computer science: Artificial intelligence). The core of the CIM concept is an integrated database that supports the manufacturing enterprise and is linked with other administrative databases.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
In nonmanufacturing service organizations the prevalent type of information system supports transaction processing. Transactions are sets of discrete inputs, submitted by users at unpredictable intervals, which call for database searching, analysis, and modification. The processor evaluates the request and executes it immediately. Portions of the processing function may be carried out at the intelligent terminal that originated the request so as to distribute the computational load. Response time (the elapsed time between the end of a request and the beginning of the reply) is an important characteristic of this type of real-time teleprocessing system. Large transaction-processing systems often incorporate private telecommunications networks.
Teleprocessing transaction systems constitute the foundation of service industries such as banking, insurance, securities, transportation, and libraries. They are replacing the trading floor of the world's major stock exchanges, linking the latter via on-line telecommunications into a global financial market. Again, the core of a transaction system is its integrated database. The focus of the system is the recipient of services rather than the system operator. Because of this, a local travel agent is able to plan the complete itinerary of a traveler--including reservations for airlines, hotels, rental cars, cultural and sports performances, and even restaurants, on any continent--and to tailor these to the traveler's schedule and budget.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
A relatively new category of service-oriented information systems is the expert system, so called because its database stores a description of decision-making skills of human experts in some narrow domain of performance, such as medical image interpretation, taxation, brickwork design, configuration of computer system hardware, troubleshooting malfunctioning equipment, or beer brewing. The motivation for constructing expert systems is the desire to replicate the scarce, unstructured, and perhaps poorly documented empirical knowledge of specialists so that it can be readily used by others.
Expert systems have three components: (1) a software interface through which the user formulates queries by which the expert system solicits further information from the user and by which it explains to the user the reasoning process employed to arrive at an answer, (2) a database (called the knowledge base) consisting of axioms (facts) and rules for making inferences from these facts, and (3) a computer program (dubbed the inference engine) that executes the inference-making process.
The knowledge base is a linked structure of rules that the human expert applies, often intuitively, in problem solving. The process of acquiring such knowledge typically has three phases: a functional analysis of the environment, users, and tasks performed by the expert; identification of concepts of the domain of expertise and their classification according to various relationships; and an interview, by either human or automated techniques, of the expert (or experts) in action. The results of these steps are translated into so-called production rules (of the form "IF condition x exists, THEN action y follows") and stored in the knowledge base. Chains of production rules form the basis for the automated deductive capabilities of expert systems and for their ability to explain their actions to users.
Expert systems are a commercial variety of a class of computer programs called knowledge-based systems. Knowledge in expert systems is highly unstructured (i.e., the problem-solving process of the domain is not manifest), and it is stated explicitly in relationships or deductively inferred from the chaining of propositions. Since every condition that may be encountered must be described by a rule, rule-based expert systems cannot handle unanticipated events (but can evolve with usage) and remain limited to narrow problem domains.
Another variant of expert systems, one that does not possess this limitation, employs a knowledge base that consists of structured descriptions of real-world problem situations and of decisions actually made by human experts. In medicine, for example, the patient record contains descriptions of personal data, physical and laboratory examinations, clinical diagnoses, proposed treatments, and the outcomes of such treatments. Given a large database of such records in a medical specialty, a physician may query the database as to decisions and events that appear analogous to those involving the present patient, so as to display the collective, real-world experience bearing on the situation. In contrast to rule-based expert systems, which are (ideally) intended to replace a human expert with a machine, knowledge bases containing descriptions of actual problem events may be used only as decision-aiding tools. They are attractive, however, because their development is usually a by-product of organizational information systems and because their usefulness (to practice, research, continuing education, and so forth) increases with the volume of expert experience they acquire.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Aside from the proliferation of organizational information systems, new types of teleprocessing systems became available for use by the public during the 1970s. With the proliferation of electronic databases, the then-new industry of "database vendors" began to make these resources available via on-line database search systems. Today this industry operates for public access and uses hundreds of document databases, some of them in full text; corporate and industry data and news; stock quotations; diverse statistics and time series; and catalogs of products and services.
Recent services of public information utilities include transaction-processing systems: brokerage services to place on-line stock, bond, and options orders; home banking to pay bills and transfer funds; travel planning and reservations; and on-line catalog shopping. Some of these services combine on-line information retrieval (from, say, merchandise catalogs) and transaction processing (placing orders). Many include such functions as electronic mail and teleconferencing.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Preoccupation with information and knowledge as an individual, organizational, and societal resource is stronger today than at any other time in history. The volume of books printed in 16th-century Europe is estimated to have doubled approximately every seven years. Interestingly, the same growth rate has been calculated for global scientific and technical literature in the 20th century and for business documents in the United States in the 1980s. If these estimates are reasonably correct, the growth of recorded information is a historical phenomenon, not peculiar to modern times. The present, however, has several new dimensions relative to the information resource: modern information systems collect and generate information automatically; they provide rapid, high-resolution access to the corpora of information; and they manipulate information with previously unattainable versatility and efficiency.
The proliferation of automatic data-logging devices in scientific laboratories, hospitals, transportation, and many other areas has created a huge body of primary data for subsequent analysis. Machines even generate new information: original musical scores are now produced by computers, as are graphics and video materials. Electronic professional workstations can be programmed to carry out any of a variety of functions. Some of those that handle word processing not only automatically look for spelling and punctuation errors but check grammar, diction, and style as well; they are able to suggest alternative word usage and rephrase sentences to improve their readability. Machines produce modified versions of recorded information and translate documents into other languages.
Modern information systems also bring new efficiency to the organization, retrieval, and dissemination of recorded information. The control of the world's information store has been truly revolutionized, revealing its diversity in hitherto unattainable detail. Information services provide mechanisms to locate documents nearly instantaneously and to copy and move many of them electronically. New digital storage technologies make it economical for some to obtain for personal possession those collections equivalent to the holdings of entire libraries and archives. Alternately, access to information resources on electronic networks permits the accumulation of highly individualized personal or corporate collections in analog or digital form or a combination of both.
As the imprint of technology expands, some of the fundamental concepts of the field, which often took centuries to evolve, are strained. For instance, information technology forces an extension of the traditional concept of the document as a fixed, printed object to include bodies of multimedia information. Because of their digital form, these objects are easy to manipulate; they are split into parts, recombined with others, reformatted from one medium to another, annotated in real time by people or machines, and readied for display in many different formats on various devices. Control of these "living" documents, which mimic human association and processing of ideas and are expected to become one of the most common units of the digital information universe, is but one of the challenges for the emerging virtual library of humankind.
An equally significant new dimension of modern information systems lies in their ability to manipulate information automatically. This capability is the result of representing symbolic information in digital form. Computer-based information systems are able to perform calculations, analyses, classifications, and correlations at levels of complexity and efficiency far exceeding human capabilities. They can simulate the performance of logical and mathematical models of physical processes and situations under diverse conditions. Information systems also have begun to mimic human cognitive processes: deductive inference in expert systems, contextual analysis in natural-language processing, and analogical and intuitive reasoning in information retrieval. Powerful information-transforming technologies now available or under development--data/text to graphics, speech to printed text, one natural language to another--broaden the availability of information and enhance human problem-solving capabilities. Computer visualization is dramatically altering methods of data interpretation by scientists; geographic information systems help drivers of the latest automobiles navigate cities; and interactive applications of networked multimedia computers may, for some, replace newspapers, compete with commercial broadcast television, and give new dimensions to the future of education and training at all levels of society.
Information systems applications are motivated by a desire to augment the mental information-processing functions of humans or to find adequate substitutes for them. Their effects have already been felt prominently in three domains: the economy, the governance of society, and the milieu of individual existence.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Information systems are a major tool for improving the cost-effectiveness of societal investments. In the realm of the economy, they may be expected to lead to higher productivity, particularly in the industrial and service sectors--in the former through automation of manufacturing and related processes, in the latter through computer-aided decision making, problem solving, administration, and support of clerical functions. Awareness that possession of information is tantamount to a competitive edge is stimulating the gathering of technical and economic intelligence at the corporate and national levels. Similarly, concern is mounting over the safeguarding and husbanding of proprietary and strategic information within the confines of organizations as well as within national borders. Computer crime, a phrase denoting illegal and surreptitious attempts to invade data banks in order to steal or modify records, or to release over computer networks software (called a virus) that corrupts data and programs, has grown at an alarming rate since the development of computer communications. In worst-case scenarios, computer crime is capable of causing large-scale chaos in financial, military, transportation, municipal, and other systems and services, with attendant economic consequences.
The growing number of information-processing applications is altering the distribution of labour in national economies. The deployment of information systems has resulted in the dislocation of labour and has already had an appreciable effect on unemployment in the United States. That country's economic recession during the early 1990s saw thousands of middle-management jobs relinquished, most permanently. The growth of computer-based information systems encourages a change in the traditional hierarchical structure of management (see below). As heavy automation is reverting production facilities from the labour-intensive nations to industrialized countries, the competitive potential of some of these nations is also likely to suffer an economic setback, at least in the short run. Singapore, a city-state of some three million people, has become very prosperous as giant foreign electronic firms located their manufacturing facilities there. It is bracing against such an economic setback by seeking to become the world's most intensive user and provider of electronic information systems for public services, international commerce and banking, and communications.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
For much of the history of humankind, formal organizations have been better equipped than the citizenry to take advantage of information: their record-keeping practices were more mature and efficient, they possessed better facilities and skills to collect and interpret information; and--with computational aids--they are now able to profit from the powerful analytical tools provided by information technology. Possession of information is not, however, tantamount to higher-quality governance or management, particularly if such possession is unilateral. As the number of recent political and financial scandals in various countries documents, it also entails possibilities of error and misuse.
It is the democratization of information, a characteristic of the last decades of the 20th century, that portends a beneficial impact on the quality of human governance and management. The public information and communication utilities that propagate this trend not only render the concerned citizen's access to information more equitable, they also help to forge informal societal networks that counterbalance the power of formal organizations and increasingly focus their style of management on consulting with the well-informed and on conveying greater concern. The concept of the "electronic town hall," an issue debated in the U.S. presidential elections of 1992, encapsulates the ideal of participatory democracy.
An environment that encourages the use of information technology and systems fosters what might be termed high information maturity on the part of the populace, a prerequisite of participatory democracy. Equitable access to information by all citizenry--rich and poor, privileged and disadvantaged--is one of the poignant societal issues facing humankind in the 21st century.
Computer-based information systems also impact the structure and management styles of corporations. The matrix organization, a structure in which departments and employees communicate directly with other organizational units, is an increasingly popular alternative to the hierarchical structure. Loose organizational decentralization imitates the observed principle of nature and of social organization suggesting that a unit size of roughly 150 persons communicates optimally and requires minimal managerial overhead. As business expansion and mergers extend the authoritative reach of large corporations and as the use of standard techniques of electronic document interchange forges flexible networks of firms in most industrial domains, leadership by consensus replaces authoritarian management. Information sharing and communication are the principal factors bringing about these changes, and information systems constitute the foundation that makes such sharing and communication effective.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
An overt impact of modern information systems concerns the individual's standard and style of living. Information systems affect the scope and quality of health care, make social services more equitable, enhance personal comfort, provide a greater measure of safety and mobility, and extend the variety of leisure forms at one's disposal. More subtly but equally important, they also affect the content and style of an individual's work and in so doing perturb the social and legal practices and conventions to which one is accustomed. New kinds of information products and media necessitate a redefinition of the legal conventions regulating the ownership of products of the human intellect. Moreover, massive data-collecting systems bring into sharp focus the elusive borderline between the common good and personal privacy, calling for the need to safeguard stored data against accidental or illegal access, disclosure, or misuse.
Individuals cannot ignore the impact of automation and information-processing systems on their skills and jobs. Information technology makes obsolete, in part or in entirety, many human functions: first mechanical and repetitive tasks were affected; now clerical and paraprofessional tasks are being automated; and eventually highly skilled and some professional functions will be made unnecessary. Individuals performing these functions face the probability of shorter periods of employment and the need to adapt or change their skills. As technologies, including information technology, grow more sophisticated, their learning curves stretch or the required skills become narrower; continuing training and education are likely to become a way of life for both employee and employer. Unlike the slow, gradual evolution of human labour in past generations, present-day changes are occurring rapidly and with little warning. Unless society members anticipate these effects and prepare to cope with them mentally and in practice, job dislocations and forced geographic relocations may prove traumatic for employees and their families.
The perhaps more fundamental issue of paramount long-term significance for society has to do with the well-being of the human spirit in an increasingly knowledge-intensive environment. In such an environment, knowledge is the principal and perhaps most valuable currency. The growing volume and the rate of obsolescence of knowledge compel the individual to live in the continuous presence of, and frequent interaction with, information resources and systems. Effective use of these resources and systems may be a modern definition of literacy, while the absence of such a skill may very well result in intellectual and possibly economic poverty and inequity. There is a real danger that humans, unwilling or incapable or not given access to information, may be relegated to an existence that falls short of the human potential.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
A wide-ranging discussion by 39 scientists on the nature and goals of the information, computer, communication, and systems sciences appears in Fritz Machlup and Una Mansfield (eds.), The Study of Information: Interdisciplinary Messages (1983). Fundamental concepts of information representation and processes are dealt with, sometimes speculatively, in Marvin Minsky, The Society of Mind (1986); Roger C. Schank, Conceptual Information Processing (1975); Allen Newell and Herbert A. Simon, Human Problem Solving (1972); Herbert A. Simon, The Sciences of the Artificial, 2nd ed., rev. and enlarged (1981); and Ronald J. Brachman, Hector J. Levesque, and Raymond Reiter (eds.), Knowledge Representation (1992). Borje Langenfors and Bo Sundgren, Information Systems Architecture (1975), explores fundamental aspects of structure and design. The impact of information technology on making human recorded knowledge available was first visualized in Vannevar Bush, "As We May Think," Atlantic Monthly, 176:101-108 (July 1945). Theodor Holm Nelson, Literary Machines, edition 90.1 (1990), presents a vision of a literary "hyperspace" in which digital representations of ideas, images, and sound are recombined at will. Reference sources can be useful for independent study of the subject, especially Dennis Longley and Michael Shain, Van Nostrand Reinhold Dictionary of Information Technology, 3rd ed. (1989); and Anthony Ralston and Edwin D. Reilly (eds.), Encyclopedia of Computer Science, 3rd ed. (1993), for the professional reader.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Jens Rasmussen, Information Processing and Human-Machine Interaction: An Approach to Cognitive Engineering (1986); and Terry Winograd and Fernando Flores, Understanding Computers and Cognition: A New Foundation for Design (1986), address interface issues arising in computer processing. A comprehensive, basic survey is offered in Steven L. Mandell, Computers and Information Processing: Concepts and Applications, 6th ed. (1992). C. Gordon Bell and John E. Mcnamara, High-Tech Ventures: The Guide for Entrepreneurial Success (1992), includes an insightful analysis of the trends in information technology. Carlo Batini, Stefano Ceri, and Shamkant B. Navathe, Conceptual Database Design: An Entity-Relationship Approach (1992), offers technical but highly readable coverage of this central area of information systems engineering. Computerized management of text is well covered in Gerard Salton, Automatic Text Processing: The Transformation, Analysis, and Retrieval of Information by Computer (1988); and traditional methods of searching text receive thorough treatment in Gerard Salton and Michael J. Mcgill, Introduction to Modern Information Retrieval (1983). Systematic, technical descriptions of computer processing of nontextual signal carriers appear in Pankaj K. Das, Optical Signal Processing (1991); and Walt Tetschner, Voice Processing, 2nd ed. (1992); and descriptions of multimedia image signals in Craig A. Lindley, Practical Image Processing in C: Acquisition, Manipulation, Storage (1991). The emphasis of James D. Foley et al., Computer Graphics: Principles and Practice, 2nd ed. (1990), is on human-machine interaction in this field of computer applications; the theory, practice, and future of virtual worlds is discussed in Howard Rheingold , Virtual Reality (1991). Martin P. Clark, Networks and Telecommunications: Design and Operation (1991), is a readable introduction to the fundamentals of computer networks, their design, and their management. Natural language understanding, expert systems, and robotics are explained competently in Patrick Henry Winston, Artificial Intelligence, 3rd ed. (1992). An engrossing introduction to information-processing applications that enable artistic expression is given in Stephen Wilson, Using Computers to Create Art (1986).
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
James I. Cash, Jr., F. Warren Mcfarlan, and James L. Mckenney, Corporate Information Systems Management: The Issues Facing Senior Executives, 3rd ed. (1992), is recommended reading for managers having responsibility for corporate information processing. An increasing list of monographs centres on the issue of cost-effectiveness of corporate information processing and computing--e.g., Marilyn M. Parker and Robert J. Benson, Information Economics: Linking Business Performance to Information Technology (1988); Paul A. Strassmann, The Business Value of Computers (1990); and Richard Veryard (ed.), The Economics of Information Systems and Software (1991). The continuous evolution of information technologies requires a disciplined approach to their use in the office, argues Charles Ray, Janet Palmer, and Amy D. Wohl, Office Automation: A Systems Approach, 2nd ed. (1991). David D. Bedworth, Mark R. Henderson, and Philip M. Wolfe, Computer-Integrated Design and Manufacturing (1991), offers a detailed description of computer-assisted functions in a manufacturing enterprise.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
The broad view of library networking in the United States given in Susan K. Martin, Library Networks, 1986-87: Libraries in Partnership (1986), remains representative of current trends. Cooperative arrangements in Europe are discussed in Karl Wilhelm Neubauer and Esther K. Dyer (eds.), European Library Networks (1990). Access guides to information resources in printed form are exemplified by Ellis Mount and Beatrice Kovacs, Using Science and Technology Information Sources (1991). Since the publication of J.S. Quarterman, The Matrix: Computer Networks and Conferencing Systems Worldwide (1990), the growth in the number and variety of electronic information resources has been so astonishing that guides to these resources are maintained predominantly in electronic form. Among the published monographs are Matthew Rapaport, Computer Mediated Communications: Bulletin Boards, Computer Conferencing, Electronic Mail, and Information Retrieval (1991), attesting to the growing popularity of informal communications via digital media; Ed Krol, The Whole Internet: User's Guide & Catalog (1992), offering comprehensive instructions for accessing the rapidly evolving virtual library of the world; and Michael Strangelove and Diane Kovacs (compilers), Directory of Electronic Journals, Newsletters, and Academic Discussion Lists, 2nd ed. (1992), pointing the reader to the newest forms of documents and communications (which includes a growing repertoire of classical literature in digital form). Readers interested in the plans of the U.S. information community may consult Association Of Research Libraries, Linking Researchers and Resources: The Emerging Information Infrastructure and the NREN Proposal (1990); the Canadian vision is described in Gary Cleveland, Research Networks and Libraries: Applications and Issues for a Global Information Network (1991).
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Seminal studies of the "information era" include Fritz Machlup, Knowledge: Its Creation, Distribution, and Economic Significance, 3 vol. (1980-84); Daniel Bell, The Coming of Post-Industrial Society: A Venture in Social Forecasting (1973); Marc Uri Porat and Michael Rogers Rubin, The Information Economy, 9 vol. (1977); and Michael Rogers Rubin, Mary Taylor Huber, and Elizabeth Lloyd Taylor, The Knowledge Industry in the United States, 1960-1980 (1986). For an example of parallel studies in Great Britain, see Ian Miles, Mapping and Measuring the Information Economy (1990). Early French views of the societal effects of the marriage of computers and telecommunications were presented in Simon Nora and Alain Minc, The Computerization of Society: A Report to the President of France (1980; originally published in French, 1978). A more recent Japanese view is summarized in Taichi Sakaiya, The Knowledge-Value Revolution; or, A History of the Future (1991; originally published in Japanese, 1985). Jack Meadows (ed.), Information Technology and the Individual (1991), discusses a range of societal implications of the technology. The importance of preserving individual freedoms in the information age is argued eloquently in Ithiel De Sola Pool, Technologies of Freedom (1983). Philip Fites, Peter Johnston, and Martin Kratz, The Computer Virus Crisis, 2nd ed. (1992), shows the dimensions of one of the hazards to be faced by corporate and public information networks in the years to come. Arthur R. Miller and Michael H. Davis, Intellectual Property: Patents, Trademarks, and Copyright in a Nutshell, 2nd ed. (1990), elaborates on issues of property rights in information.
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.
Useful series of printed reviews in information science include Annual Review of Information Science and Technology; Advances in Computers (irregular); and Advances in Artificial Intelligence in Software Engineering (annual). Major abstracting journals in computing include Computing Reviews (monthly); ACM Guide to Computing Literature (annual); Computer Literature Index (quarterly); Computer Abstracts (monthly); and Computer Book Review (monthly), surveying new publications in a broad range of subjects on computing. Useful secondary sources that list publications dealing with information science and systems include Information Science Abstracts (monthly); and Library & Information Science Abstracts (monthly), containing abstracts of literature on librarianship and archives, documentation, publishing, dissemination of information, and mass communications.
(V.Sl.)
Copyright ® 1994-2001 Encyclop?dia Britannica, Inc.