Набросок LALR генераторa
00: S → C C
01: C → c C
02: C → d

| . | c | d | $ | S | C
|
| 0 | s3 | s2 | . | . | 1
|
| 1 | s3 | s2 | . | . | 4
|
| 2 | r2 | r2 | r2 | . | .
|
| 3 | s3 | s2 | . | . | 5
|
| 4 | . | . | r0 | . | .
|
| 5 | r1 | r1 | r1 | . | .
|
Самая самая первая версия
Пока что происходит простая генерация с выводом результатов. Не читается файл с живой граматикой, граматика зашита в исходник.
Не создаются файлы с рабочими таблицами, просто выводится результат. Не рассматриваются приоритеты операций.
В приоритетах в целом нет ничего особого, простой устдаление конфликта,
Происходит простая генерация результата. Более того исходник я просто буквально набрал и работу его не проверял, но он очень неплохо работает.
Записываются два файла: HTML с таблицей парсера, и dot файл с графом конечного автомата.
Немного применяется stl (на минимальном уровне).
В парсере нет такого состояния как accept. Для того чтобы его приделать нужно иметь отдельную строку в граматике (какой-то корневой элемент).
Иногда можно взять существующий нетерминал как корень (если он не содержит рекурсии), в таком случае ввод дополнительного корня будет избыточен.
Описывать подробно все рассуждения не охота. Проще говоря accept происходит автоматом внутри самого парсера в тот момент,
когда в тексте появляется конец файла, а на стеке остаётся один символ. В целом нормально работает.

Первый пре релиз
файлы будут обновляться, по мере исправления мелких ошибок. Некоторые места достаточно грубо переделывались.
Вообще пока всё сыровато, но будет доведено до ума по мере того как я буду применять эту штуку:
- work.y - основная граматика для теста
- dump.html - результат генерации для граматики с выражением
- doc.html - описание (документ)
- lalr.rar - всё сразу одним архивом
В целом всё работает. Только сжатие не слишком быстрым получилось. И обработка ошибок сложнее чем хотелось бы.
Из планов только привести всё это в более приличный вид. Особенно сделать более аккуратный парсер и часть генерирующую исходник.
Не ещё некоторые недоработки, до которых руки не дошли.
Для использования достаточно указать программе файл с граматикой: lalr.exe +d work.y.
Есть так же пара недоделанных механизмов. Один из них это снижение нагрузки на стек, который я даже и делать уже не хочу.
Суть этих механизмов проста. В процессе работы самого автомата, некоторые из терминалов не несут в себе никаких значений, и не влияют на дальнейшую работу, изменяется только состояние конечного автомата.
На подобные терминалы можно не расходовать стек. Например:
expr: ( expr ) ;
S: if expr then S;
В данном случае не обязательно заносить на стек такие токены как if, then, (, ), достаточно просто изменять состояние автомата.
Конешно если ( ) используется для восстановления ошибок, то одну скобку на стек засунуть придётся.
Текущая бетта (последний исходник)
Немного навёл порядок внутри исходников генератора. Растащил всё по разным файлам. STL почти убран, остались только вектора.
Строки, карты, списки, устроены по своему. Строки разделяют данные в памяти, отдельные копии отслаиваются в момент модификации.
Вобщем меняю много и уже не слежу за этим. Пока что залил исходник на sf.net, но заниматься им некогда, хотя ещё буду.
Можно брать текущую версию здесь (в названии опечатался когда проект создавал, но это не важно):
svn co https://casini.svn.sourceforge.net/svnroot/casini casini
|
Немного о структурах
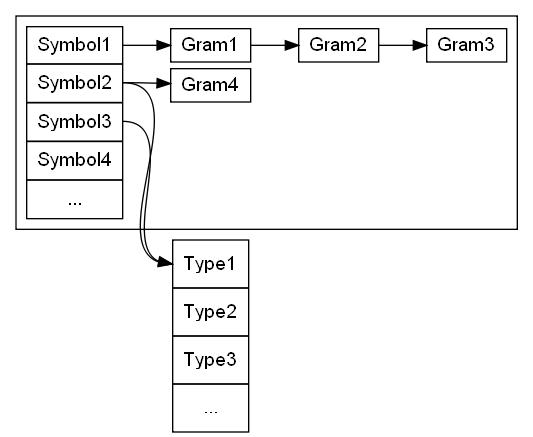
- Symbol - символ, т.е. его название, номер, тип. Символы уникальны и хранятся в списке.
- Type - тип символа или поле которое будет добавлено в труктуру типа (в union или рядом). Типы хранятся в списке.
- Gram - правило из граматики. Просто последовательнсть символов, имеющая номер. Правила ввиде односвязанного списка подвешиваются на симсол с которого одна начинаются. Так же правила отдельно соединяются в общий список, чтобы их можно было перечислить не трогая список символов.
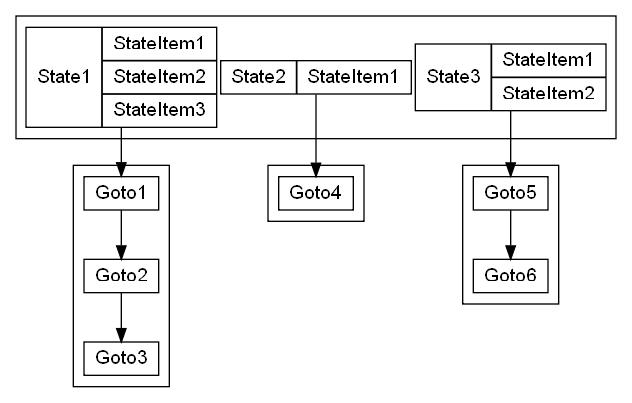
- StateItem - минимальная делать конечного автомата. Строка граматики и сдвиг внутри этой строки (позиция точки)
- State - состояния конечного автомата. Набор правил (строк) из граматики и сдвигов точек внутри этих строк. Состояния хранятся в списке.
- Goto - переходы между состояниями конечного автомата. Структуры которые подвешиваются ввиде списков к состояниям автомата, и содержат
в себе переходы на другие состояния, свёртки, или ссылки ошибки.
- Error - структура с описанием ошибки. Служит только для обработки ошибок, баланса скобок.
Запись исходника
Для создания таблицы в исходнике используется промежуточное представление.
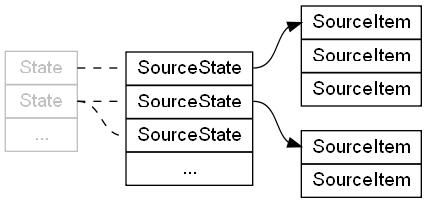
- SourceItem - строка которая будет записана в таблице готового исходника. Соответструет одному элементу Goto в ядре.
- SourceState - набор строк, т.е. элемент который содержит список из SourceItem элементов и которому соотвествует один элемент State в ядре.
Грубого говоря он содержит некий отрезок списока, на который могут ссылаться другие SourceItem элементы. Т.е. одному State элементу, может соотвествовать
несколько SourceState элементов. Cписки внутри SourceState можно перестраивать как угодно, не опасаясь ничего испортить.