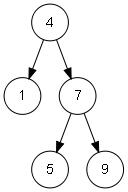
тут любой ребёнок справится:
struct node_st{char value; node_st *p1,*p2;}*root=0;
void insert(char value)
{
node_st *node,**p=&root;
while(node=*p) p=(node->value>value)? &node->p1: &node->p2;
*p=node=new node_st;
node->value=value;
node->p1=node->p2=0;
}
node_st *find(char value)
{
node_st *node=root;
while(node) {
if(node->value==value) break;
node=(node->value>value)? node->p1: node->p2;
}
return node;
}
for(int n=0; n<5; n++) insert("41759"[n]);
|
У этой системы есть недостатки: 1) ест относительно много памяти, на каждый символ выделяется по структуре. 2) не слишком быстро работает с этой памятью, большой разброс данных.
Сама структура узла дерева имеет размер 12 байт. В хороших компиляторах в зависимости от устройства распределителя памяти на неё будет тратится 16 или 32 байта. Что будет в Visual studio 2003 и выше, я даже думать не хочу, там распределитель был просто убран и отсутсвует полностью. Если написать собсвенный распределитель, но это мало поможет, либо будет 16 байт на структуру, либо выраванивать их придётся по 12 или 9 байт (если упаковать char).
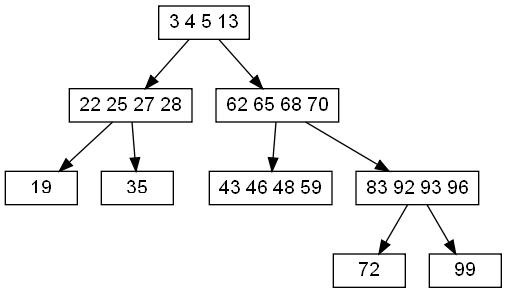
Каждый узел дерева содержит сортированный массив. Если в нём есть свободное место мы вставляем новое число,
если надо спускаемся вниз под дереву и работаем с ниже стоящими узлами. При работе с таким деревом, есть только одна мелкая неприятность.
Если по какой-то причине у нас есть узлы с неполными массивами, то мы не можем вставлять в крайние позиции массива,
поскольку они ограничивают значения дочерних узлов, и подобная вставка собьёт ограничения. Чтобы всем было понятно, покажу не примере:
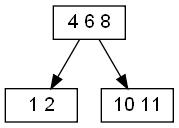
Мы хотим вставить в дерево число '9', в массиве корневого узла есть место, но вставить число в корневой узел мы не можем.
Мы может вставить в корень числа '5' или '7', а появление '9' в корне, нарушит свойства бинарного дерева поиска.
Проще говоря во время разнородных вставок и удалений из такого дерева, не узлы истощаются и пустеют,
очень медленно, но безвозвтарно. Поэтому мы может либо на давать им истощаться слишком сильно,
либо всегда держать их полными. В первом случае после удаления и возвращаем массив в полное состояние с помощью нового значения,
подтянутого откуда-нибудь из листьев дерева.
Есть методы менее эффективные, но более простые и практичные. Весь фокус в том что частично балансом можно управлять, меняя своё поведение во время вставки и удаления. Это можно сделать в двух местах:
Ещё одна, занятная стратегия балансировки заключается в том чтобы всё таки не поддерживать, узлы дерева полными, а востанавливать их наполненость в случае заметного истощения. Недостающие элементы массивов восполняются из листьев. Исходник с отложенной балансировкой прилагается: